Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Pakistan
146 Aufträge abgeschlossen
Ich liefere Qualität! 24 Stunden verfügbar
Level 2
Hat hohe Leistungskriterien erfüllt und verfügt über eine nachgewiesene Erfolgsbilanz bei der Erfüllung von Kundenerwartungen.
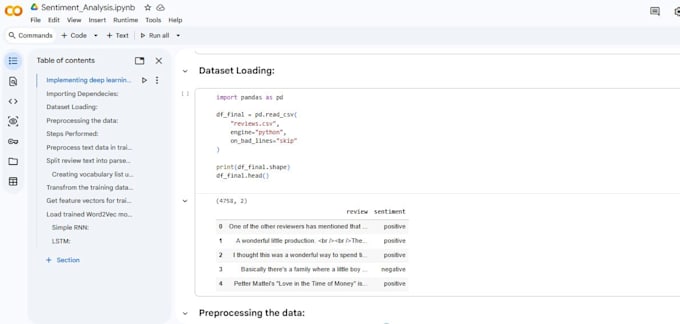
Ich biete professionelle End-to-End-Lösungen für Stimmungsanalysen mit Python und Natural Language Processing (NLP) für Unternehmen, Startups und Forscher, die umsetzbare Erkenntnisse aus Textdaten gewinnen möchten. Ich arbeite mit Kundenbewertungen, Social-Media-Inhalten, Umfragen, Support-Tickets und Feedback-Daten, um Stimmungs- und Meinungs-Trends zu extrahieren, die datenbasierte Entscheidungen unterstützen.
Mein Workflow umfasst fortschrittliche Textvorverarbeitung (Normalisierung, Tokenisierung, Stop-Wort-Entfernung, Lemmatisierung), Feature-Engineering mit TF-IDF, N-Grammen oder Wort-Embeddings sowie die Entwicklung von Modellen mit Machine Learning und Deep Learning Algorithmen wie Logistische Regression, SVM, Naive Bayes und LSTM-basierte Architekturen. Die Modelle werden anhand von Genauigkeit, Präzision, Recall, F1-Score und Verwirrungsmatrizen bewertet, um eine zuverlässige Leistung zu gewährleisten.
Du erhältst sauberen, modularen und gut dokumentierten Python-Code, reproduzierbare Experimente und visuelle Analysen für die geschäftliche Interpretation. Ich unterstütze CSV, Excel, JSON und Textformate und kann Lösungen für binäre oder multi-klassige Sentiment-Klassifikation, Skalierbarkeit und zukünftige Implementierung anpassen.
Bitte kontaktiere mich vor der Bestellung, um den Projektumfang, die Dataset-Größe


Automatische Übersetzung
Welche Art von Sentiment-Analyse bietest du an?
Ich biete binäre (positiv/negativ) und multi-klassige (positiv/neutral/negativ) Sentiment-Analysen mit Machine Learning und Deep Learning Modellen an, abhängig von der Komplexität des Projekts und der Datenmenge.
Welche Programmiersprache und Tools verwendest du?
Ich verwende Python mit branchenüblichen NLP- und ML-Bibliotheken wie NLTK, SpaCy, Scikit-learn, TensorFlow/Keras, Pandas und NumPy.
Können Sie mit großen Datensätzen umgehen?
Ja. Ich kann große Datensätze (über 50.000 Einträge) effizient verarbeiten und Modelle hinsichtlich Leistung und Skalierbarkeit optimieren.
Bietest du Deep Learning-basierte Sentiment-Analysen an?
Ja. Für fortgeschrittene Anforderungen erstelle ich LSTM- oder embedding-basierte Deep Learning-Modelle, um eine höhere Genauigkeit bei komplexen Textdaten zu erreichen.
Erhalte ich den Quellcode?
Absolut. Du erhältst sauberen, gut dokumentierten und wiederverwendbaren Python-Code zusammen mit Erklärungen zum Workflow.