Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Data Scientist, AI Solutions Engineer, Agentic AI Spezialist
Unordentliche Daten bremsen dich aus? Die meisten Data-Science-Projekte scheitern an schlechter Datenqualität. Ich bin hier, um zu helfen. Ich biete fachkundige Datenbereinigung, explorative Datenanalyse (EDA) und Feature Engineering an, um sicherzustellen, dass deine Daten genau, aufschlussreich und "modellbereit" sind.
Was ich anbiete:
1. Professionelle Datenbereinigung
2. Tiefgehende explorative Datenanalyse (EDA)
3. Fortgeschrittenes Feature Engineering
Tools & Technologien:
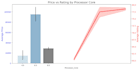
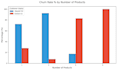
Ich verwende Python mit branchenüblichen Bibliotheken: Pandas, NumPy, Seaborn, Matplotlib und Scikit-learn.
Lieferumfang: Du erhältst einen bereinigten Datensatz (CSV/Excel) und ein vollständig dokumentiertes Jupyter Notebook (.ipynb) mit allen Codes und Visualisierungen.


Automatische Übersetzung
Was muss ich für den Einstieg bereitstellen?
Bitte stelle dein Dataset im CSV-, Excel- oder SQL-Format bereit, zusammen mit einer kurzen Beschreibung deiner Ziele. Wenn du spezielle Fragen hast, die die Explorative Datenanalyse (EDA) beantworten soll, kannst du sie gerne auflisten!
Welche Tools verwendest du für Datenbereinigung und EDA?
Ich benutze hauptsächlich Python mit leistungsstarken Bibliotheken wie Pandas und NumPy für die Datenmanipulation sowie Matplotlib oder Seaborn für hochwertige Datenvisualisierungen.
Kannst du sehr unordentliche Datensätze mit fehlenden Werten bearbeiten?
Ja! Das ist meine Spezialität. Ich verwende fortschrittliche Imputationstechniken (Mittelwert, Median, Modus oder prädiktive Füllung) und Ausreißererkennung, um sicherzustellen, dass deine Daten konsistent sind und für die Analyse bereitstehen.
Was ist "Feature Engineering" und warum brauche ich das?
Feature Engineering ist der Prozess, bei dem aus deinen Rohdaten neue Variablen erstellt werden, um Machine-Learning-Modelle zu verbessern. Zum Beispiel das Umwandeln einer "Datum"-Spalte in "Wochentag" oder "Feiertag". Es bringt erheblichen Mehrwert für deine Vorhersagemodelle.
Worauf bezieht sich "100 Items Cleaned" in deinen Paketen?
Im Bereich Datenbereinigung setzt Fiverr eine Mindestanzahl von 100 Items fest. Ich betrachte diese "Items" als Datenpunkte oder Zeilen. Mein Basic-Paket ist darauf ausgelegt, hochwertige Reinigung und EDA für Standard-Datensätze zu bieten. Wenn deine Datei mehrere Tausend Zeilen hat, mach dir keine Sorgen – ich kann das innerhalb des aufgelisteten Pakets erledigen.
Bekomme ich den Quellcode?
Absolut. Ich liefere ein gut dokumentiertes Jupyter Notebook (.ipynb) oder Python-Skript, damit du genau sehen kannst, wie die Daten transformiert und in Zukunft neu erstellt wurden.
Sind meine Daten bei Ihnen sicher?
Ja, ich nehme den Datenschutz sehr ernst. Deine Daten werden nur für den Umfang des Projekts verwendet und nach Abschluss und Annahme der Bestellung von meinem System gelöscht.


