Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD




Automatische Übersetzung
Hör auf, Umsätze durch schlechte Suche zu verlieren.
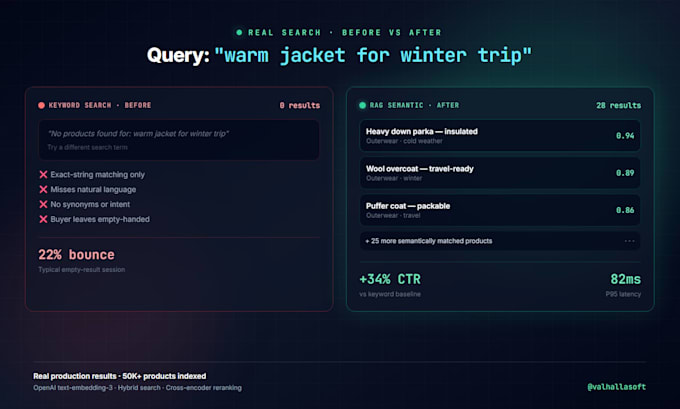
Wenn deine Ecommerce-Suche keine Ergebnisse liefert, wenn Kunden natürliche Anfragen statt exakter SKUs eingeben, lässt du Geld liegen. Ich setze produktionsreife RAG- und semantische Suche um, die Absicht versteht, nicht nur Keywords.
Konkretes Beispiel: Ich leite derzeit die Migration der AI-Suche für einen der größten Händler Lateinamerikas (über 200 Filialen, 1 Mio+ Nutzer täglich, 50K+ Produkte) und ersetze die Google Search API durch ein RAG-basiertes System, das jährlich 500.000 Dollar einsparen soll.
Was du bekommst:
Stack: Python (FastAPI), OpenAI / sentence-transformers, AWS, Docker, Kubernetes.
Warum ich: Über 10 Jahre Erfahrung im Aufbau skalierter Backend-Systeme. Senior Platform Engineer mit teamübergreifender Architekturverantwortung. Ich liefere getestete Ergebnisse und dokumentiere, damit dein Team das System nach der Übergabe übernimmt.
Schick mir eine Nachricht mit deinem Stack, Kataloggröße und was an deiner aktuellen Suche nicht funktioniert. Ich antworte innerhalb einer Stunde mit konkreten nächsten Schritten.
Senior RAG and AI Search Engineer for Backend at Scale
Sprachen
Automatische Übersetzung
Automatische Übersetzung
Welche Vektor-Datenbank sollte ich verwenden?
Das hängt von Umfang, Kosten und Betriebsanforderungen ab. Ich helfe dir bei der Entscheidung zwischen Pinecone (verwaltet), Weaviate (self-hosted), Qdrant (Open Source) und pgvector (keine neue Infrastruktur). Das Architecture-Review-Paket beinhaltet diese Entscheidung.
Wie viel kostet die OpenAI-Embedding-API?
Für 50K Produkte mit OpenAI text-embedding-3-small kosten die initialen Indexierung etwa 1-2 USD. Die Abfrage-Embedding-Kosten liegen bei etwa 0,00002 USD pro Suche. Ich füge Kostenprognosen in Standard- und Premium-Pakete ein.
Kannst du mit meinem bestehenden Such-Backend integrieren?
Ja. Hybride Suche, die dein bestehendes Keyword-Backend mit semantischen Vektoren kombiniert, schlägt meist reine Semantik. Ich integriere mit Elasticsearch, Algolia, Typesense, OpenSearch und Meilisearch.