Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Experte für Machine Learning, prädiktive Modelle und Datenbereinigung
Produktionstaugliche KI benötigt makellose Daten. Egal, ob du ein RAG-System aufbaust oder ein Modell wie Llama 3, GPT oder ein anderes LLM feinabstimmen möchtest, gilt die absolute Regel: "Garbage In, Garbage Out".
Interesse: Ich bin ein KI-Spezialist, der die kritische, zeitaufwändige Datenverarbeitung übernimmt, damit dein Projekt vorankommt. Ich "teile" Texte nicht nur, sondern nutze semantische Logik, um sicherzustellen, dass deine KI den Kontext behält, hohe Genauigkeit erreicht und reasoning-Fähigkeiten besitzt.
Wunsch: Services, die ich für deine KI-Infrastruktur anbiete:
Aktion: Hör auf, Zeit mit Datenbereinigung zu verschwenden, und fang an zu bauen. Ich liefere den hochwertigen Treibstoff für deine KI-Maschine. Schick mir dein Dataset-Beispiel für ein individuelles Angebot noch heute!


Technik:
Anleitung
Tagging-Typ:
Text
Automatische Übersetzung
In welchen Formaten lieferst du für Feinabstimmung?
Ich liefere im .jsonl-, .csv- oder .json-Format, perfekt formatiert für die Anforderungen deines Zielmodells (z.B. ChatML oder Alpaca-Formate).
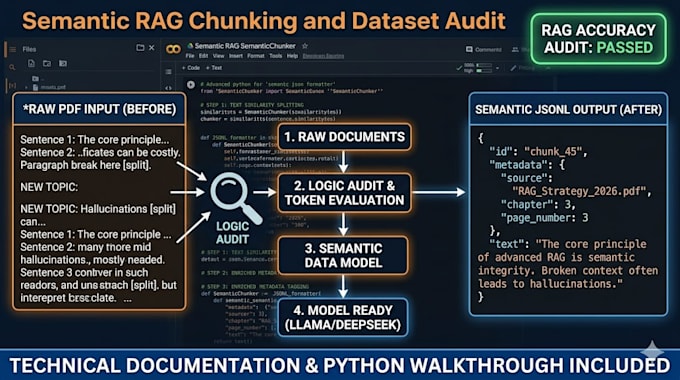
Kannst du große technische Dokumente für RAG verarbeiten?
Ja. Ich nutze Python-basiertes semantisches Splitten, um sicherzustellen, dass Überschriften, Tabellen und logische Absätze zusammenbleiben, was für die RAG-Genauigkeit entscheidend ist. Ich kann auch agentisches Splitten verwenden.
Stellst du in diesem Gig den finalen AI-Bot bereit?
Nein. Das ist ein Data Engineering Gig. Ich liefere die verarbeiteten Datensätze und chunked Knowledge Bases, die deine KI zum Funktionieren braucht.
Sind meine Daten sicher und privat?
Absolut. Ich halte mich strikt an die Datenschutzrichtlinien von Fiverr. Alle Kundendaten werden vertraulich behandelt und nach Abschluss der Bestellung dauerhaft von meinem lokalen Rechner gelöscht.