Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
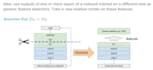
Satzklassifikation mit vortrainierten Sprachmodellen und Transferlernen.
Erreiche höhere Genauigkeit mit weniger Daten
Über 90 % Genauigkeit bei zwei Klassen und 100 Beispielen.
Mehr Beispiele sind besser (> 50 pro Klasse)
Schnelleres Training
Für Leute, die sich mit dem Thema nicht auskennen: Da wir über Klassifikatoren sprechen, befinden wir uns im Bereich des überwachten Lernens im maschinellen Lernen. Das bedeutet, wir brauchen einen gelabelten Datensatz, um ein solches Modell zu trainieren.
Der gelabelte Datensatz könnte eine Liste von Nachrichten sein, die als Spam oder Nicht-Spam gekennzeichnet sind.
Oder Sentiment-Analyse von Film-, Musik- oder Produktbewertungen, die positiv/negativ/neutral gelabelt sind oder Kategorien wie Ambiente, Angebote, Service, Sicherheit, Komfort zugeordnet sind.
Oder Kategorisierung technischer Dokumente, Spezifikationen, die in Prozessor-Dokumentation, Computer, WLAN-Router oder Möbel, Beleuchtung, Gartenarbeit, Badezimmer, Außenbereich klassifiziert sind. Das funktionierende Modell kann in Google Colab oder als Streamlit-App eingerichtet werden, die Text oder Dokumente liest und Klassifikationen zurückgibt oder lokal mit einem Jupyter-Notebook ausgeführt wird.

Expertise:
Klassifizierung
Programmiersprache:
Python
Frameworks:
scikit-learn
•
PyTorch
•
Panda
•
Andere
Tools:
Jupyter-Notizbuch
•
Andere


