Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
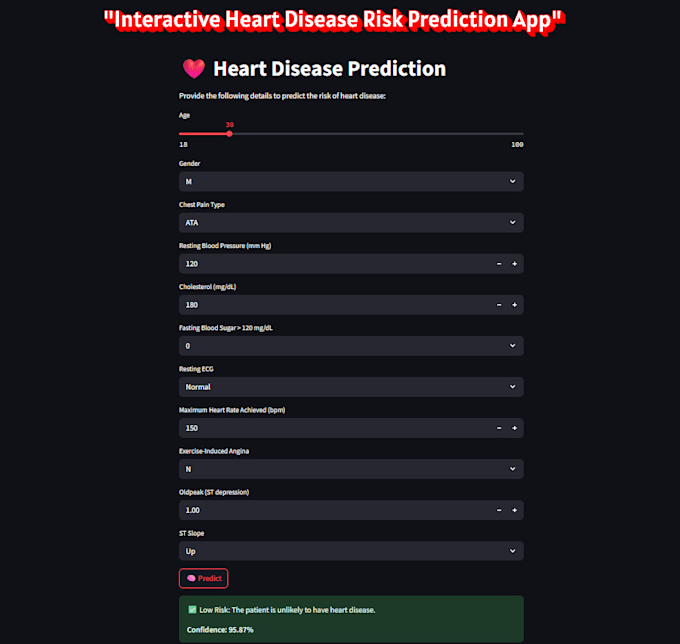
Daten reinigen, analysieren und visualisieren in einer Lösung
Ich werde eine vollständige Datenanalyse durchführen und Machine-Learning-Modelle erstellen, um dir zu helfen, genaue, datenbasierte Vorhersagen mit Python, Pandas und scikit-learn zu treffen.
Von Datenbereinigung, explorativer Datenanalyse (EDA) und Umgang mit fehlenden Werten bis hin zum Training von ML-Modellen und deren Einsatz mit Flask oder FastAPI biete ich End-to-End-Lösungen, die auf deine Bedürfnisse zugeschnitten sind.
Was du bekommst:


Technologie:
Excel
•
Google Sheets
•
Python
•
SQL
Automatische Übersetzung
Q: Mit welchen Arten von Daten kannst du arbeiten?
A: Ich kann mit strukturierten Datensätzen wie CSV, Excel, JSON oder SQL-Datenbanken arbeiten. Ob Vertrieb, Gesundheitswesen, Marketing, Finanzen oder andere Bereiche — ich helfe dir, deine Daten zu bereinigen, zu analysieren und zu modellieren.
Q: Welche Machine-Learning-Modelle verwendest du?
A: Ich nutze beliebte ML-Modelle wie Lineare Regression, Logistische Regression, Entscheidungsbäume, Random Forest, XGBoost, Support Vector Machines (SVM), KNN und mehr — abhängig von deinen Daten und Zielen.
Q: Welche Tools und Bibliotheken verwendest du?
A: Ich verwende hauptsächlich Python mit Bibliotheken wie Pandas, NumPy, matplotlib, seaborn, scikit-learn, XGBoost und für Deployment Flask oder FastAPI.
F: Erklären Sie mir die Ergebnisse?
A: Absolut! Ich liefere klare Visualisierungen, Zusammenfassungsberichte und Erklärungen der Modellresultate, damit du verstehst, was das Modell macht und was die Vorhersagen bedeuten.
Q: Kannst du das Modell als API bereitstellen?
A: Ja, im Gold-Paket biete ich API-Integration mit Flask oder FastAPI, damit dein Modell in Anwendungen oder auf Websites genutzt werden kann.
Q: Erhalte ich den Quellcode und die Modell-Dateien?
A: Ja, ich liefere das vollständige Jupyter Notebook, die trainierte Modell-Datei (.pkl oder .joblib) und alle zusätzlichen Dateien wie Berichte oder Visualisierungen — basierend auf deinem gewählten Paket.
Q: Kannst du fehlende Werte und Ausreißer behandeln?
A: Ja, ich identifiziere und behandle fehlende Daten und Ausreißer nach bewährten Methoden, um sicherzustellen, dass dein Datensatz sauber und bereit für das Modelltraining ist.