Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Data Engineer, ETL, APIs und BI-Automatisierung
Was ich machen kann:
Vollständige Datenquellenanbindung (Multi-Source / komplexe Pipelines)
API-Integration + externe Systemintegration
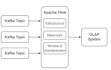
Erweiterte Flink-Funktionen (Checkpointing, Zustandsverwaltung, Windowing, Joins)
Systemoptimierung & Performance-Tuning
Architekturdesign-Beratung
Formatierung & Aufräumen
Kompletter Quellcode + Dokumentation inklusive
„Absolut großartiger Data Engineer. Er hat unsere Kafka-zu-Flink-Streaming-Pipeline für unser MVP einwandfrei eingerichtet. Der Code war sauber, gut dokumentiert und pünktlich geliefert.“
-- David L., Tech Lead
„Wir hatten Schwierigkeiten mit Zustandsverwaltung und Windowing in unserem Echtzeit-ETL-Prozess. Er hat nicht nur unsere Bugs behoben, sondern auch die gesamte Flink-Architektur optimiert. Sehr zu empfehlen für komplexe Datenströme!“
-- Alex R., Datenarchitekt
„Schnell, professionell und tiefgehende Expertise in Apache Flink. Er hat nahtlos mehrere externe APIs in unseren Datenfluss integriert und die Performance perfekt für die Produktion abgestimmt. Wird wieder engagiert.“
-- Sarah M., Gründerin eines Startups



Expertise:
Big Data
•
Datenfluss
•
etl
Technologie:
Apache Kafka
•
Apache-Funken
•
Java
•
Python
•
Scala
•
Andere


