Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD



Automatische Übersetzung
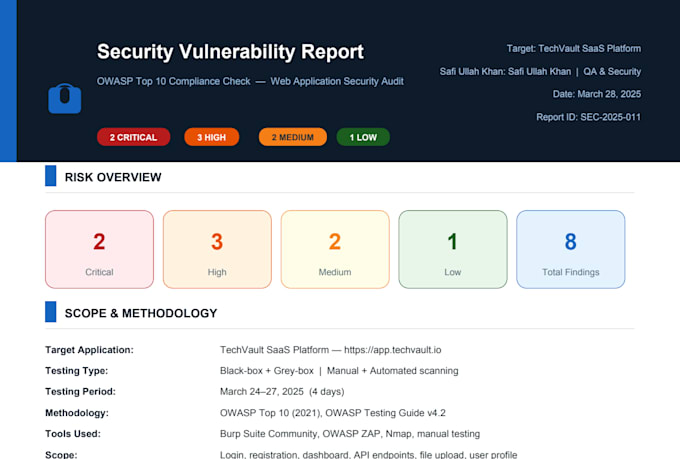
Stellst du ein LLM oder ein autonomes KI-System bereit? Wenn deine Anwendung sich mit APIs, Datenbanken oder Benutzereingaben verbindet, könnte sie anfällig für Prompt-Injection, Datenlecks und Tool-Missbrauch sein. Meine AI Agent Security-Dienste erkennen kritische Schwachstellen, bevor Angreifer sie ausnutzen.
Als Experte für Cybersicherheit führe ich LLM-Red-Teaming durch, um Prompt-Injection, Jailbreaks, Tool-Hijacking und unsichere Ausgaben zu entdecken. Jeder LLM-Red-Teaming-Einsatz stärkt deine AI Agent Security-Position.
Was ich anbiete:
Fortgeschrittenes LLM-Red-Teaming für Jailbreaks und Umgehung von Sicherheitsbarrieren.
Umfassende AI Agent Security-Audits für Prompt-Injection und Datenlecks.
Threat Modeling für RAG-Pipelines, Vektor-Datenbanken und AI-Agenten.
Proaktives AI Agent Security-Testing auf unbefugte Tool- und API-Ausführung.
Lieferumfang:
Ein detaillierter LLM-Red-Teaming-Bericht mit Proof-of-Concept-Ergebnissen und entwicklerorientierten Maßnahmen zur Verbesserung deiner AI Agent Security.
Meine LLM-Red-Teaming-Methodik folgt den OWASP Top 10 für LLMs und MITRE ATLAS. Ich spezialisiere mich auf AI Agent Security, um dir zu helfen, sichere KI-Anwendungen mit Vertrauen zu deployen. LLM-Red-Teaming ist unerlässlich, bevor du ein Produktions-KI-System startest.
Python Automation , Web Security, AI Agents Security, Cloud Security
Sprachen
Automatische Übersetzung
Automatische Übersetzung
Was ist der Unterschied zwischen einem LLM-Pentest und einem Sicherheits-Check für AI-Agenten?
Ein LLM-Pentest konzentriert sich hauptsächlich auf die Eingaben und Ausgaben des Modells (Jailbreaks, Prompt-Injection). AI-Agenten-Sicherheitstests gehen tiefer – sie prüfen, wie ein autonomer Agent mit Tools, Datenbanken und APIs interagiert, um sicherzustellen, dass bösartige Prompts den Agenten nicht dazu zwingen können, unautorisierte Aktionen auszuführen
Brauchst du Zugriff auf meinen Quellcode?
Nicht unbedingt. Ich kann Black-Box-AI-Red-Teaming einfach durchführen, indem ich auf die Benutzeroberfläche oder den API-Endpunkt deiner Anwendung zugreife. Allerdings ermöglicht der Zugang zu System-Prompts oder Architekturdiagrammen eine viel gründlichere White-Box-Sicherheitsprüfung für AI.