Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Lass uns maschinelles Lernen für deine Ziele nutzbar machen!
Über mich
Hallo! Ich bin Sivanandham, ein Machine Learning Spezialist mit nachweislicher Erfahrung in Finanzprognosen, Aktienmarktvorhersagen und datengetriebener Automatisierung. Mit über 2 Jahren praktischer Erfahrung in Künstlicher Intelligenz, Machine Learning, Datenanalyse, Data Science und KI-Systemen.
Ich habe mehr als 25 reale ML-Projekte umgesetzt, die tatsächlich Geschäftsprobleme gelöst haben, nicht nur akademische Demos.
Meine Dienstleistungen:
ML-Modellentwicklung: Klassifikation, Regression
Pipeline-Schritte: Datenaufnahme, Datenbereinigung & Vorverarbeitung, Feature Engineering, Modelltraining, Hyperparameter-Optimierung, Validierung & Vorhersage
Modelltraining & Bewertung: Genauigkeit, F1-Score, ROC-AUC
Modelloptimierung: Evaluationsmetriken, GridSearchCV
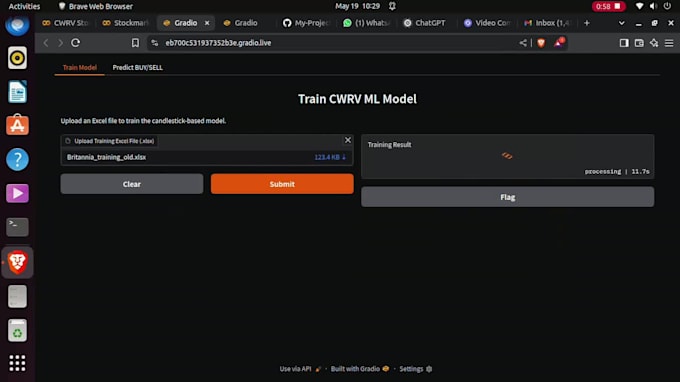
Modellbereitstellung: Gradio-basierte Apps, lokale Bereitstellung
Tools & Technologien:
Sprachen & Bibliotheken: Python, Pandas, NumPy, Matplotlib, Seaborn, Gradio, Excel, Scikit-learn
ML-Algorithmen: Entscheidungsbäume, Support Vector Machine (SVM), Logistische/Lineare Regression, Gradient Boosting, Kreuzvalidierung, Grid Search
Versionskontrolle: GitHub
Tipp: Bevor du eine Bestellung aufgibst, schick mir eine Nachricht mit deinem Dataset, deinen Zielen und Erwartungen, damit ich den richtigen Plan und Zeitrahmen für dich erstellen kann




Programmiersprache:
Python
•
Colab
Frameworks:
scikit-learn
•
PyTorch
•
Panda
APIs:
Google Cloud Vision API
Tools:
Jupyter-Notizbuch
•
opencv
•
Excel
•
MLflow
•
Colab
Automatische Übersetzung
Kannst du mit meinem Rohdatensatz arbeiten oder muss er bereinigt sein?
Ja, ich kann mit Rohdaten arbeiten. Ich biete vollständige Datenbereinigung (ETL), Vorverarbeitung und Transformation an, um deinen Datensatz ML-ready zu machen — inklusive Umgang mit fehlenden Werten, Ausreißern und Formatierungsproblemen.
Welche Leistungen erhalte ich?
Du erhältst Python-Code (sauber und gut kommentiert), Leistungsvisualisierungen (Verwirrungsmatrix, ROC-Kurve, Feature-Importance), Modell-Erklärungen und einsatzbereite Dateien.
Wie stellst du sicher, dass das Modell gut funktioniert?
Ich verwende bewährte Techniken wie Kreuzvalidierung, Train-Test-Split, Bias-Variance-Analyse und Hyperparameter-Tuning (GridSearchCV), um optimierte und robuste Modelle zu erstellen.
Wie wähle ich zwischen Basic, Standard und Advanced Paketen?
● Basic ist ideal für einfache Anwendungsfälle oder Anfänger. ● Standard umfasst vollständige Vorverarbeitung, Ungleichgewichtsausgleich und Feinabstimmung — perfekt für kleine Unternehmen. ● Advanced bietet produktionsreife Modelle, Vergleich mehrerer Algorithmen und UI — ideal für Profis und Forschungsprojekte.
Werden meine Daten vertraulich behandelt?
Absolut. Deine Daten werden vertraulich behandelt und niemals geteilt oder wiederverwendet.
Wie weiß ich, dass dein Service zuverlässig ist?
Mit über 25 realen ML-Projekten, fortgeschrittenem Training (6-monatige KI-Zertifizierung von Novi Tech) und nachweisbaren Geschäftsergebnissen (z.B. 2166 % Wachstum durch ML-Insights) liefere ich strukturierte, erklärbare und wirkungsvolle Modelle, die auf deine Ziele zugeschnitten sind.
Kannst du Dokumentation oder Notebook-Erklärungen liefern?
Ja. Ich kann das Projekt in einem Jupyter Notebook Format oder Google Colab mit Schritt-für-Schritt-Erklärungen, Kommentaren und visuellen Ausgaben liefern, um das Verständnis und die Wiederverwendung zu verbessern.
Welche Datensatzgröße kannst du verarbeiten?
Ich kann mit kleinen bis mittelgroßen Datensätzen effizient arbeiten. Es können individuelle Angebote gemacht werden, um eine optimierte Leistung durch effiziente Speichertechniken zu gewährleisten.
Welche speziellen Data-Science-Dienstleistungen bietest du an?
Ich biete eine Vielzahl von Dienstleistungen an, darunter Datenbereinigung und -vorverarbeitung, explorative Datenanalyse, prädiktives Modellieren, Feinabstimmung, Entwicklung von Machine-Learning-Algorithmen, Datenvisualisierung und umsetzbare Erkenntnisse.
Wie gewährleisten Sie die Vertraulichkeit und Sicherheit meiner Daten?
Deine Daten werden streng vertraulich behandelt. Alle sensiblen Daten werden in sicheren Umgebungen verarbeitet und nicht online hochgeladen oder auf Online-Plattformen verarbeitet: Deine Daten sind nur für dich und die auf meinem Laptop laufende Jupyter Notebook zugänglich.