Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Leitender Dateningenieur
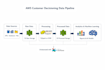
Ich bin ein Senior Data Engineer mit über 6 Jahren Erfahrung in der Entwicklung skalierbarer Datenpipelines und Cloud-Datenplattformen. Ich spezialisiere mich auf den Aufbau zuverlässiger ETL-Workflows, die Umwandlung roher Daten in strukturierte Datensätze und die Ermöglichung analytischer Daten-Systeme.
Ich kann dir bei folgenden Aufgaben helfen:
-Entwicklung von ETL-Pipelines mit Python, SQL und Pyspark
-Datenaufnahme von APIs, Dateien und Datenbanken
-Datenumwandlung und -optimierung
-Cloud-Datenpipelines mit AWS (S3, EMR, Redshift, Glue, Kinesis, Athena)
-Lakehouse-Architektur (Bronze-, Silver- und Gold-Schichten)
-Datenlagerintegration und Performance-Optimierung
Mein Fokus liegt auf dem Aufbau effizienter, skalierbarer und produktionsbereiter Datenpipelines, die Analysen, Berichte und Machine-Learning-Workflows unterstützen.
Wenn du Hilfe bei der Gestaltung oder Verbesserung deiner Datenpipeline oder Datenplattform brauchst, kontaktiere mich gern, bevor du eine Bestellung aufgibst.

Warehouse-Plattform:
Snowflake
•
redshift
•
PostgreSQL / Greenplum
Projektart:
New Build
