Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Vollständiger Stack AI Engineer LangChain RAG GPT4 NextJS FastAPI
Verliert dein Geschäft Geld durch Betrug, den du nicht erkennen kannst?
Ich entwickle ML-gestützte Betrugserkennungssysteme, die das aufdecken, was manuelle Regeln übersehen – mit echter, messbarer Genauigkeit.
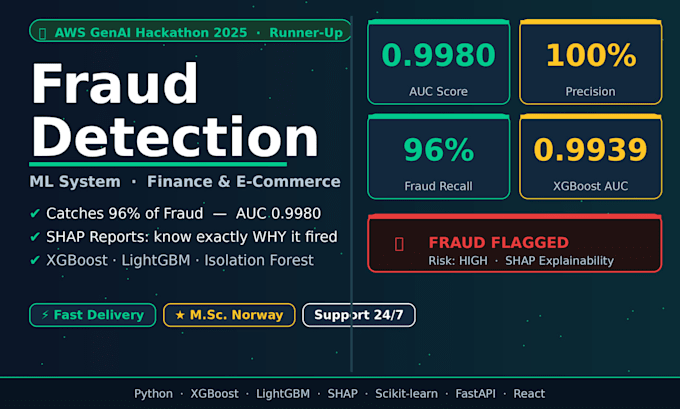
BEWIESENE LEISTUNG:
- XGBoost: AUC 0.9939 | Präzision 1.0 | Recall 0.96
- Ensemble-System: AUC 0.9980
- SHAP-Erklärbarkeit – jede Markierung hat einen Grund
WAS ICH BEREITSTELLE:
- Datenvorverarbeitung & Feature Engineering
- Multi-Modell-Training (XGBoost, Random Forest, LightGBM)
- Anomalieerkennung & Risikobewertung
- SHAP-Erklärberichte
- ROC-Kurve, Konfusionsmatrix, Präzisions-Rücklauf-Analyse
- Sauberer, dokumentierter Jupyter Notebook + Quellcode
- REST API & Streamlit-Dashboard (Premium)
BESTE ANWENDUNG FÜR:
- Fintech-Startups & Banken
- E-Commerce-Rückbuchungsprobleme
- Versicherungsbetrug bei Schadensfällen
- AML-Compliance-Teams
TECH: Python | XGBoost | LightGBM | Scikit-learn | SHAP | FastAPI | Streamlit
LIEFERUMFANG: Quellcode, Bewertungsbericht, Visualisierungen, Jupyter Notebook
Funktioniert mit deinem Datensatz ODER Standarddatensätzen (Kreditkarten, PaySim, Versicherungsdaten).
Kontaktiere mich vor der Bestellung, um deinen Anwendungsfall zu besprechen.


Automatische Übersetzung
Welche Art von Daten benötigst du, um das Betrugserkennungsmodell zu erstellen?
Ich kann mit deinem eigenen Datensatz (CSV, Excel oder Datenbank-Export) arbeiten oder branchenspezifische Standarddatensätze wie den Kreditkartenbetrug-Datensatz, PaySim oder Versicherungsansprüche verwenden. Kontaktiere mich vor der Bestellung, um die Datenquelle abzustimmen.
Welche Algorithmen für maschinelles Lernen verwenden Sie?
Ich nutze XGBoost, LightGBM, Random Forest, Isolation Forest und Deep-Learning-Modelle inklusive Autoencoder und LSTM für die Erkennung zeitlicher Muster. Die Wahl hängt von deiner Datenmenge und deinen Bedürfnissen ab. Ich empfehle das beste Modell.
Verstehe ich, warum eine Transaktion markiert wurde?
Ja. Alle Modelle beinhalten SHAP-Erklärberichte, damit du genau siehst, welche Features jede Betrugsmarkierung verursacht haben. Das ist entscheidend für Compliance, Audits und den Aufbau von Vertrauen bei Stakeholdern.
Werden meine Daten vertraulich behandelt?
Absolut. Deine Daten werden ausschließlich für dieses Projekt verwendet und niemals geteilt oder wiederverwendet. Auf Wunsch kann ich vor Beginn der Arbeit eine NDA unterschreiben.
Welche Leistungen werde ich erhalten?
Du erhältst sauberen, gut dokumentierten Python-Quellcode, ein Jupyter Notebook mit Schritt-für-Schritt-Erklärung, Modellbewertungsbericht mit Visualisierungen (ROC-Kurve, Konfusionsmatrix, SHAP-Diagramme) und eine Requirements-Datei für eine einfache Einrichtung. Das Premium-Paket beinhaltet außerdem eine REST API und ein Streamlit-Dashboard.
Funktioniert das auch für andere Betrugsarten außer Zahlungsbetrug?
Ja. Das System funktioniert für Versicherungsbetrug, E-Commerce-Rückbuchungsbetrug, Kontoübernahme-Erkennung, AML-Transaktionsüberwachung und mehr. Kontaktiere mich mit deinem spezifischen Anwendungsfall vor der Bestellung.
Muss ich gelabelte Daten (Betrug vs. kein Betrug) bereitstellen?
Nicht unbedingt. Wenn du gelabelte Daten hast, erstelle ich ein überwacht lernendes Modell für höhere Genauigkeit. Wenn nur Rohdaten ohne Labels vorliegen, verwende ich unüberwachte Anomalieerkennung (Isolation Forest, Autoencoder), um verdächtige Muster zu identifizieren.
Kann das nach der Lieferung in Produktion eingesetzt werden?
Die Basic- und Standard-Pakete liefern einsatzbereiten Code, den du lokal oder auf jedem Server laufen lassen kannst. Das Premium-Paket beinhaltet eine REST API und eine einsatzbereite Deployment-Umgebung. Cloud-Deployment (AWS, GCP, Azure) ist als kostenpflichtiges Extra verfügbar.