Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Data Science und Künstliche Intelligenz
Suchst du mehr als nur ein einfaches NLP-Skript?
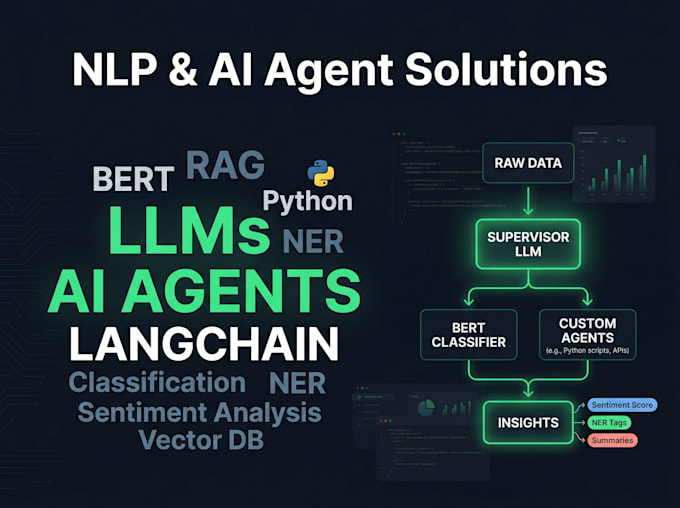
Ich baue intelligente Textsysteme von klassischen NLP-Pipelines bis hin zu feinabgestimmten BERT-Modellen und produktionsreifen AI-Agenten, die von LangGraph und LangChain angetrieben werden. Ob du einen Sentiment-Classifier, einen domänenspezifischen Chatbot oder ein vollständiges Multi-Agenten-LLM-System brauchst – ich liefere saubere, dokumentierte und einsatzfähige Lösungen.
Was ich anbiete:
1. NLP & Textanalyse
Textvorverarbeitung: Tokenisierung, Stopword-Entfernung, Lemmatisierung (spaCy / NLTK)
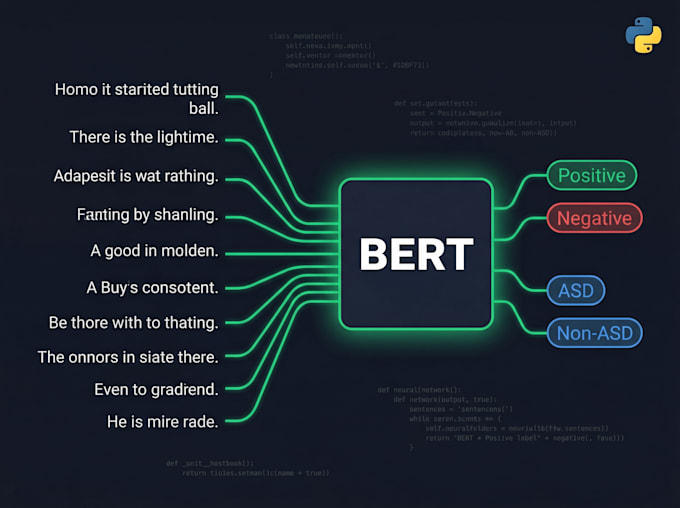
Textklassifikation & Sentiment-Analyse (Naive Bayes, SVM, Logistische Regression)
Named Entity Recognition (NER), Keyword- & Keyphrase-Extraktion
TF-IDF, N-Gramm-Analyse, Wortfrequenz, Co-Occurrence-Netzwerke
Themenmodellierung LDA, NMF, BERTopic
Textzusammenfassung & Semantische Ähnlichkeit
2. BERT & Transformer Feinabstimmung
Feinabstimmung von BERT, RoBERTa, DistilBERT, AraBERT auf deinem eigenen Datensatz
Sequenzklassifikation, Token-Klassifikation, Fragebeantwortung
Trainingskurven, Evaluationsbericht (Genauigkeit, F1, Konfusionsmatrix)
Modelle speichern & exportieren (HuggingFace-Format, .pth, .zip)
3. AI-Agenten & LLM-Lösungen
Multi-Agenten-Orchestrierung mit LangGraph, domänenspezifisch



Programmiersprache:
Python
•
MATLAB
•
SQL
•
Colab
Frameworks:
scikit-learn
•
PyTorch
•
Panda
APIs:
Andere
Tools:
Jupyter-Notizbuch
•
opencv
•
tensorflow
•
Excel
•
Colab
Automatische Übersetzung
Q1: Mit welchen Textdaten kannst du arbeiten?
Jede Domäne — medizinischer/klinischer Text, Kundenrezensionen, Social-Media-Posts, YouTube-Kommentare, rechtliche Dokumente, wissenschaftliche Arbeiten, Finanzberichte, Umfrageantworten. Wenn du Text hast, kann ich daraus etwas bauen.
Q2: Brauche ich ein gelabeltes Dataset für die Klassifikation?
Bei überwachten Aufgaben (Klassifikation, Sentiment) — ja, gelabelte Daten sind notwendig. Bei unüberwachten Aufgaben (Themenmodellierung, Clustering, Keyword-Extraktion) — reicht roher Text. Ich kann dir auch bei der Label-Strategie beraten, wenn du ganz neu anfängst.
Q3: Kannst du ein RAG-System für meine Dokumente oder Wissensdatenbank bauen?
Ja — das fällt unter das Premium-Paket. Ich richte einen Vektor-Store (FAISS oder Chroma) ein, verbinde ihn mit deinen Dokumenten und baue eine LangChain-Retrieval-Pipeline, damit dein LLM Fragen ausschließlich aus deinen Daten beantwortet.
Q4: Mit welchen LLMs arbeitest du?
OpenAI GPT-3.5 / GPT-4, Groq (LLaMA 3, Mixtral), Google Gemini, Mistral. Ich kann mit jedem arbeiten, den du bevorzugst oder für den du bereits API-Zugang hast. Alternativ kann ich auch Open-Source-Modelle lokal über Ollama nutzen, um API-Kosten zu sparen.
Q5: Kannst du das Modell oder den Agenten als API oder Web-App bereitstellen?
Grundlegende Bereitstellung (FastAPI-Endpunkt oder Streamlit-App) kann als Extra hinzugefügt werden. Für vollständige Cloud-Deployments (AWS, GCP, Hugging Face Spaces) kontaktiere mich vor der Bestellung für ein individuelles Angebot.
F6: Kannst du das Modell oder den Agenten als API oder Web-App bereitstellen?
Grundlegende Bereitstellung (FastAPI-Endpunkt oder Streamlit-App) kann als Extra hinzugefügt werden. Für eine vollständige Cloud-Bereitstellung (AWS, GCP, Hugging Face Spaces) kontaktiere mich vor der Bestellung für ein individuelles Angebot.