Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Deine Ideen in Lösungen, Websites und digitales Wachstum verwandeln!
STECKT DEINE DATEN IN DER VERGANGENHEIT FEST? ES IST ZEIT, ECHT ZU WERDEN
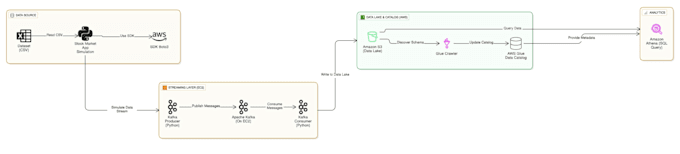
Ich bin ein spezialisierter Cloud Data Engineer mit Erfahrung im Aufbau hochleistungsfähiger Datenarchitekturen. Kürzlich habe ich eine Echtzeit-Streaming-Pipeline für Aktienmärkte entwickelt, die mit Apache Kafka und AWS massive Datenvolatilität bewältigen kann, und ich werde diese gleiche Unternehmensqualität auch für dein Business erstellen.
Mein Technischer Stack:
Was ich Für Dich Erstellen Werde:
Warum Mich Wählen? Anders als generische Entwickler verstehe ich Finanzdaten. Mein Code ist modular, gut dokumentiert und einsatzbereit.
️
BITTE SCHREIBE MIR VOR DER BESTELLUNG, UM DEINE SPEZIFISCHEN ARCHITEKTUR-BEDÜRFNISSE ZU BESPRECHEN!

Automatische Übersetzung
Muss ich meine eigenen AWS-Kontozugangsdaten bereitstellen?
Ja. Damit ich die Pipeline deployen kann, benötige ich einen IAM-Benutzer mit entsprechenden Berechtigungen (S3, EC2, Redshift). Ich kann dir zeigen, wie du das sicher erstellst, ohne dein Root-Passwort zu teilen.
Wird das Ausführen dieser Pipeline teuer auf meiner AWS-Rechnung?
Ich plane auf Kosteneffizienz. Ich nutze, wo möglich, Ressourcen, die für "Free Tier"-Nutzer geeignet sind (wie t2.micro-Instanzen für Kafka), und konfiguriere S3-Lifecycle-Policies, um alte Daten zu archivieren und so deine laufenden Kosten niedrig zu halten.
Bietest du Support, wenn die Pipeline nach der Lieferung ausfällt?
Ja. Die Standard- und Premium-Pakete beinhalten eine Support-Phase (5-7 Tage) nach der Lieferung, um Bugs im Zusammenhang mit meinem Code zu beheben. Ich gebe auch eine Anleitung, wie man Dienste neu startet, falls sie stoppen.
Welche API nutzt du, um Börsendaten abzurufen?
Ich verwende typischerweise yfinance oder Alpha Vantage für Echtzeitsimulationen. Das Pipeline ist jedoch modular. Ich kann das "Producer"-Skript austauschen, um Daten von jeder gewünschten Finanz-API zu ingestieren (z.B. Polygon.io oder IEX Cloud).
Wie gehst du mit hoher Volatilität oder Daten-Spikes am Markt um?
Die Architektur nutzt Apache Kafka als Puffer. Wenn der Aktienmarkt einen massiven Datenanstieg sendet, speichert Kafka diese sicher in der Queue, bis die Consumers (Spark/Python) sie verarbeiten können, sodass keine Daten bei hohem Traffic verloren gehen.
Warum nutzt du Zookeeper in dieser Architektur?
Zookeeper verwaltet die Kafka-Broker. Es verfolgt den Status der Kafka-Knoten und überwacht, welche Topics und Partitionen aktiv sind. Es ist essenziell für die Fehlertoleranz des Streaming-Clusters.
Wie "echtzeitnah" ist die Datenverarbeitung?
Die Latenz ist äußerst gering. Der Kafka Producer holt die Aktienkurse sofort ab, und der Consumer verarbeitet sie in nahezu Echtzeit (meist innerhalb von Millisekunden bis wenigen Sekunden), was es für Live-Dashboards geeignet macht.
In welchem Format speicherst du die Daten in S3?
In der Regel speichere ich Daten im Parquet- oder CSV-Format. Parquet ist für Finanzdaten sehr zu empfehlen, da es komprimiert und spaltenorientiert ist, was Abfragen via AWS Athena oder Redshift deutlich beschleunigt und günstiger macht.
Handhabt diese Pipeline doppelte Daten?
Ja. Ich implementiere Logik im Consumer-Skript (mit Spark oder Python Pandas), um Duplikate anhand von Zeitstempeln und Aktien-IDs zu entfernen, bevor die endgültigen, bereinigten Daten in deine Datenbank geladen werden.
Kann ich diese Pipeline an ein Dashboard wie PowerBI oder Tableau anschließen?
Absolut. Da die finalen Daten in AWS Redshift oder S3 landen, kannst du PowerBI, Tableau oder AWS QuickSight direkt verbinden, um die Live-Aktientrends zu visualisieren.