Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Big-Data-Ingenieur
Level 2
Hat hohe Leistungskriterien erfüllt und verfügt über eine nachgewiesene Erfolgsbilanz bei der Erfüllung von Kundenerwartungen.
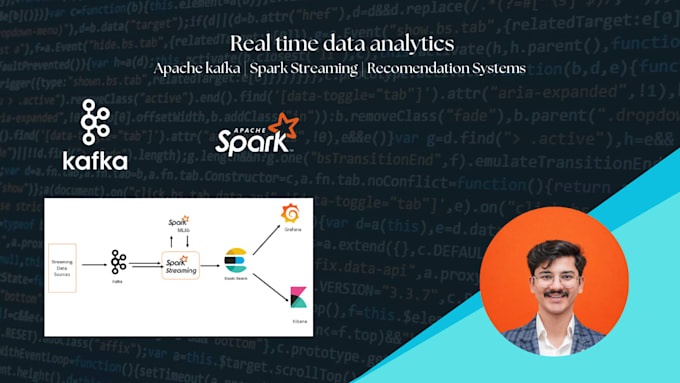
Moderne Anwendungen erzeugen riesige Echtzeit-Datenströme von Websites, mobilen Apps, IoT-Geräten und Cloud-Plattformen. Diese Daten effizient zu verarbeiten erfordert skalierbare Streaming-Architekturen und zuverlässige Datenpipelines.
Ich bin ein Dateningenieur, spezialisiert auf Big Data Systeme und Echtzeitverarbeitung, und ich helfe dir, hochleistungsfähige Streaming-Pipelines mit Technologien wie Apache Kafka und Apache Spark zu entwerfen und umzusetzen.
Ich habe Erfahrung im Aufbau von verteilten Datensystemen und groß angelegten Analyse-Pipelines, inklusive eines Echtzeit-Musikempfehlungssystems, das über 100GB Streaming-Daten mit Hadoop und Spark verarbeitet hat, sowie Echtzeit-ETL-Pipelines mit Data Warehousing für Unternehmensanalysen.
Technologien
Beispielanwendungen
Ich konzentriere mich auf den Aufbau skalierbarer, zuverlässiger und produktionsreifer Streaming-Pipelines, die Live-Daten in umsetzbare Erkenntnisse verwandeln.
Kontaktiere mich, bevor du eine Bestellung aufgibst, um deine Anforderungen zu besprechen.