Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Was wir machen
Wichtige Dienstleistungen
Prozess
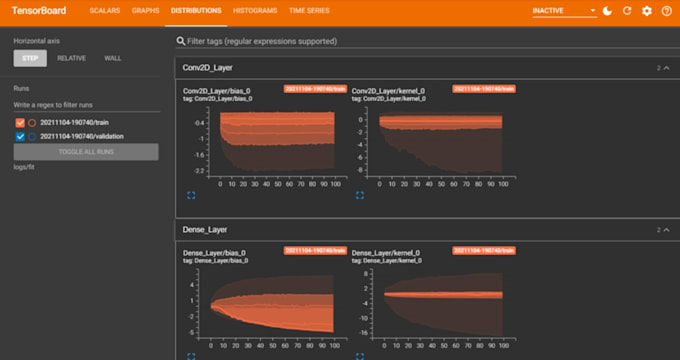
Stack
PyTorch, TensorFlow, HF, scikit-learn, Optuna, MLflow, ONNX/TensorRT, Docker/FastAPI
Eigentum
Du besitzt Code und Gewichte. Cloud-GPU-Kosten werden nach Anbieterpreisen abgerechnet. NDA/White-Label verfügbar.
Zum Start

Programmiersprache:
Python
•
MATLAB
•
Colab
•
MLflow
•
Julia
Frameworks:
scikit-learn
•
DeepPy
•
keras
•
PyTorch
•
Panda
•
tensorflow
Automatische Übersetzung
Werden Sie ein NDA unterschreiben?
Ja. Ich bin mit NDA und/oder einer gegenseitigen Vertraulichkeitsklausel einverstanden. White-label-Arbeiten sind ebenfalls in Ordnung.
Wie schützen Sie meine Daten?
Minimalprivilegierter Zugriff, private Repos, verschlüsselte Speicherung (bei Cloud-Nutzung) und keine Weitergabe an Dritte. Ich lösche Datensätze und Artefakte auf Wunsch oder 14 Tage nach Übergabe.
Wem gehört das Modell und der Code?
Dir. Vollständige Übertragung der trainierten Gewichte, des Quellcodes und der Dokumentation. Hinweis: Basis-Modelle/Open-Source-Bibliotheken behalten ihre ursprünglichen Lizenzen.
Was sind typische Lieferzeiten?
Basic: 7 Tage, Standard: 14 Tage, Premium: 28 Tage. Extra-schnelle Optionen sind in den Extras erhältlich.
Was kann die Zeitpläne beeinflussen?
Datenmenge/-qualität, Labeling, Anzahl der HPO-Versuche, Compliance-Anforderungen und Komplexität der Bereitstellung (Cloud, Skalierung, Sicherheit).
Kannst du das Modell für die Produktion bereitstellen?
Ja. Premium umfasst Cloud-Bereitstellung; Standard liefert eine API-Grundlage. Ich kann eine Dockerisierte REST-API mit Health Checks und Dokumentation bereitstellen.
Welche Stacks unterstützt du?
PyTorch/TensorFlow, Hugging Face, ONNX/TensorRT, FastAPI + Docker. Ich integriere mit AWS/GCP/Azure, Vercel/DO oder deinem eigenen Server.
Bekomme ich Exporte für Mobile/Edge?
Ja, Modell-Export nach ONNX; TFLite/Core ML auf Anfrage, abhängig von der Kompatibilität des Modells.
Was ist in der Dokumentation enthalten?
Setup-Hinweise, Run-Befehle, Endpunkt-Spezifikationen, Bewertungsbericht und eine Model Card mit Metriken, Daten und Einschränkungen.
Bieten Sie Wartung an?
Ja. Optional ist monatliche Wartung (Fehlerbehebungen, kleine Updates) als Extra oder individueller Plan möglich.