Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD



Automatische Übersetzung
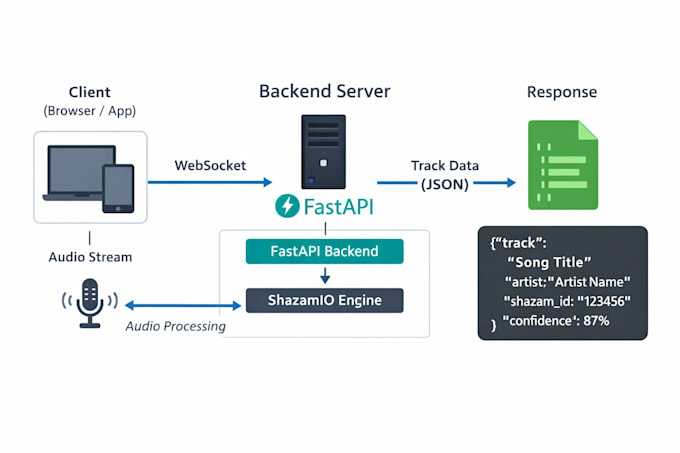
Erhalte ein produktionsfertiges Backend, das Songs in Echtzeit aus Live-Mikrofon-Audio erkennt. Perfekt für Musik-Apps, Karaoke-Tools, Forschungsprojekte oder jeden Service, der zuverlässige Song-Erkennung braucht – alles in Python mit minimalem Setup.
Was du bekommst:
Audioeingabe: rohes PCM (browserfreundlich)
Ausgabe: strukturierte JSON-Events
Optionale Upgrades beinhalten einen Demo-Client und Docker-Deployment.
Song im Demo-Video:
Song: Rameses B - ALL IN MY HEAD
Musik bereitgestellt von NoCopyrightSounds
Kostenlos
I build AI powered revenue automations for ecommerce brands
Sprachen
Automatische Übersetzung
Automatische Übersetzung
Kann ich dieses Backend mit einem Browser-Client verwenden?
Ja! Das Backend empfängt rohe PCM- oder WAV-Daten über WebSocket, sodass du Audio direkt aus einem Browser mit MediaRecorder oder Bibliotheken wie WavTools streamen kannst.
Warum verwendet es 10-Sekunden-Chunks statt eines kontinuierlichen gleitenden Fensters?
Feste 10-Sekunden-Chunks machen das System einfacher, zuverlässiger und leichter zu integrieren. Sie stellen sicher, dass ShazamIO genügend Audio für eine genaue Erkennung hat, ohne den Server zu überlasten.
Kann ich die Chunk-Länge oder Fenstergröße ändern?
Technisch ja, aber es könnte die Genauigkeit beeinträchtigen. 10 Sekunden sind die empfohlene Balance zwischen Geschwindigkeit und Zuverlässigkeit der Erkennung.
Bietet das Backend Lyrics oder Streaming-Audio an?
Nein. Der Dienst gibt nur Track-Metadaten (Titel, Künstler, Shazam-Track-Schlüssel und Vertrauensscore) zurück.
Welche Audioformate werden unterstützt?
Das Backend erwartet rohes PCM/WAV. Der Client übernimmt die Mikrofonaufnahme und Konvertierung, bevor es gesendet wird. Intern wird FFmpeg für die notwendige Umwandlung in MP3-Bytes für ShazamIO verwendet.
Kann das in Produktion laufen?
Ja! Das Docker-Paket bietet ein einsatzbereites Backend, das für Apps, Bots oder andere Echtzeit-Audioerkennungsprojekte geeignet ist.
Was, wenn ShazamIO einen Track nicht erkennt?
Du erhältst ein no_match JSON-Ereignis. Die Erkennung hängt von Shazams Datenbank ab, daher sind manche Tracks möglicherweise nicht erkennbar.
Wie schnell ist die Erkennung?
Die Erkennung erfolgt in 10-Sekunden-Chunks, daher beträgt die Verzögerung typischerweise die Dauer des Chunks plus Netzwerk-Latenz und ShazamIO-Verarbeitungszeit.