Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Qualifizierter Freelancer, der sich für qualitativ hochwertige Inhalte einsetzt
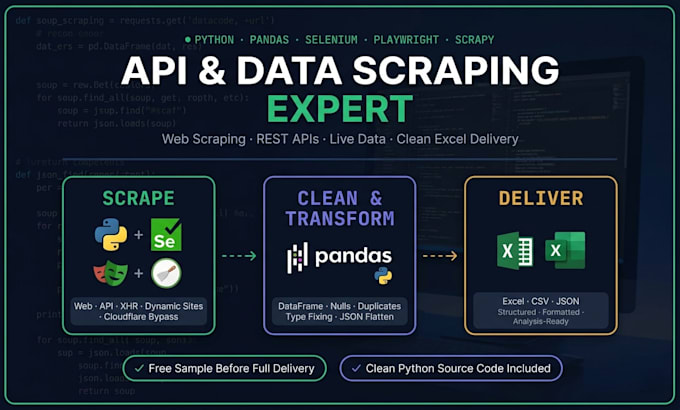
Ich werde dynamische Websites und API-Endpunkte scrapen.
Benötigst du Daten von einer beliebigen Website, versteckten API oder Live-Feed, strukturiert, bereinigt und einsatzbereit? Du bist hier genau richtig.
Ich kümmere mich sowohl um dynamisches Web-Scraping als auch um API-Endpunkt-Extraktion von JavaScript-gerenderten Seiten bis hin zu reverse-engineerten XHR/Fetch-APIs und liefere alles durch eine vollständige Pandas-Bereinigungs- und Formatierungs-Pipeline.
WAS DU BEKOMMST:
Dynamisches Website-Scraping
API-Endpunkt-Entdeckung & Reverse Engineering (XHR/Fetch)
REST API Scraping, Tokens, Auth-Headers, Session-Handling
Cloudflare, Turnstile & Anti-Bot-Umgehung
Echtzeit-Daten wie Sportergebnisse, Krypto, Preise, Listings
Verschachtelte JSON in strukturierte Tabellen umgewandelt
Excel / CSV / JSON Ausgabe
️ STACK:
Python · Pandas · Selenium · Playwright · Scrapy · Requests · BeautifulSoup · openpyxl
WARUM ICH:
Sowohl Web-Scraping als auch API-Extraktion aus einer Hand, volle Abdeckung
Kostenlose Probe vor vollständiger Lieferung
Wiederverwendbares Python-Skript bei jeder Bestellung inklusive
Nur bereinigte, getypte und formatierte Dateien, keine Rohdaten
Turnstile & Cloudflare Spezialist
Schreib mir zuerst für eine Machbarkeitsprüfung, unverbindlich.


 (1)_kv3che.jpg)
 (1)_h3ydiz.jpg)
Technologie:
Python
•
Excel
•
Selen
•
Beautiful Soup
•
Pandas
Informationstyp:
Websites
Technik:
Automatisiert
Automatische Übersetzung
Q1: Was ist der Unterschied zwischen Web-Scraping und API-Scraping?
Web-Scraping extrahiert Daten direkt aus dem HTML einer Website — nützlich für Seiten ohne öffentliche API. API-Scraping greift die versteckten Backend-Aufrufe einer Seite ab (XHR/Fetch-Anfragen), um sauberere, schnellere und zuverlässigere Daten zu erhalten. Ich mache beides — je nachdem, was für deine spezielle Seite das beste Ergebnis liefert.
Q2: Kannst du JavaScript-gerenderte oder dynamische Websites scrapen?
Ja. Ich nutze Selenium und Playwright, um JavaScript-Seiten vollständig zu rendern, unendliches Scrollen, Lazy Loading und AJAX-Inhalte zu handhaben, bevor ich Daten extrahiere — so bleibt nichts unbemerkt.
Q3: Kannst du Cloudflare oder Turnstile-Schutz umgehen?
Ja. Ich habe praktische Erfahrung im Erfassen von Cloudflare Turnstile-Tokens, inklusive scroll-triggered und user-agent-basierte Challenges — eines der komplexesten Bot-Schutzsysteme. Schreib mir mit deiner Zielseite für eine kostenlose Machbarkeitsprüfung.
Q4: Was bedeutet "Datenbereinigung und -formatierung" eigentlich?
Vor der Lieferung durchläuft jeder Datensatz eine vollständige Pandas-Pipeline: Nullwerte werden behandelt, Duplikate entfernt, Datentypen korrigiert, Spaltennamen standardisiert, verschachtelte JSON-Daten abgeflacht und Excel mit passenden Überschriften und Spaltenbreiten formatiert. Du erhältst eine fertige, professionelle Datei — kein Rohdaten-Export.
Q5: Bekomme ich das Python-Skript?
Ja — jede Bestellung enthält sauberen, kommentierten, wiederverwendbaren Python-Quellcode, damit du den Scraper jederzeit selbst erneut laufen lassen kannst, ohne erneut zu beauftragen.
Q6: In welchen Formaten lieferst du die Daten?
Standardmäßig Excel (.xlsx), CSV und JSON. Lieferung per Google Sheets auf Anfrage. Bitte gib deine Präferenz vor der Bestellung an.
Q7: Ist Web-Scraping legal?
Ich arbeite nur mit öffentlich zugänglichen Daten und scrappe keine Seiten, die dies in ihren Nutzungsbedingungen ausdrücklich verbieten. Ich extrahiere niemals private Nutzerdaten oder umgehe Bezahlschranken. Schreib mir mit deiner Ziel-URL vor der Bestellung, damit ich Machbarkeit und Einhaltung prüfen kann.
F8: Wie fange ich an?
Schreib mir vor der Bestellung. Teile deine Ziel-URL, die benötigten Datenfelder und das ungefähre Volumen. Ich bestätige Machbarkeit, Zeitplan und technische Herausforderungen — völlig kostenlos, unverbindlich.