Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Wo Daten auf Intelligenz treffen!
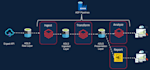
Ob du mit großen Datensätzen arbeitest, ETL-Prozesse aufbaust oder Cloud-Dienste integrierst, ich kann eine maßgeschneiderte Lösung erstellen, die deinen Bedürfnissen entspricht. Mit jahrelanger Erfahrung als Data Engineer sorge ich dafür, dass deine Pipeline optimiert, sicher und skalierbar ist, um wachsende Datenmengen zu bewältigen.
Was ich anbiete:
Technologien und Sprachen, die ich verwende:
Sprachen:
o Python
o SQL
o Scala
o Shell Scripting
Big Data Tools:
o Apache Spark
o Apache Hadoop
o Apache Kafka
o Apache Airflow
o DBT (Data Build Tool)
o Snowflake
Datenbanken:
o PostgreSQL
o MySQL
o MongoDB
o Redis
o Amazon Redshift
Cloud-Dienste:
Amazon Web Services (AWS)
Google Cloud Platform (GCP)
Microsoft Azure
Ich helfe dir, die Kraft deiner Daten freizusetzen.
Viele Grüße,
Salman Sajid

Automatische Übersetzung
Kannst du große Projekte bewältigen?
Absolut, ich kann große Projekte managen. Melde dich gerne, um die Details zu besprechen, bevor du eine Bestellung aufgibst.
Was muss ich bereitstellen, um ein Projekt zu starten?
Teile bitte detaillierte Informationen über deine Daten, die erwarteten Ergebnisse und alle spezifischen Tools oder Plattformen, mit denen du arbeiten möchtest.


