Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD

Automatische Übersetzung
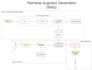
Ich bin ein RAG-Ingenieur, spezialisiert auf das Design und die Bereitstellung produktionsreifer Retrieval-Augmented Generation (RAG)-Pipelines für Unternehmens-Wissensdatenbanken. Meine Systeme garantieren hochpräzise Antworten, indem sie LLMs (GPT-4, Llama usw.) direkt mit deinen Daten verbinden.
Ich verwandle unzuverlässige Prototypen in skalierbare, geschäftskritische Anwendungen.
Was ich liefere:
End-to-End RAG-Entwicklung: Kompletter Pipeline-Aufbau, von Datenaufnahme bis Deployment.
Vektor-Datenbank-Expertise: Implementierung und Optimierung mit FAISS, Milvus und ChromaDB.
Fortschrittliche Retrieval-Methoden: Engineer Hybrid Search (Sparse + Dense) und dynamische Kontext-Injektion für maximale Relevanz und Recall.
Skalierbarkeit & Leistung: Entwicklung intelligenter Chunking-, Embedding-Update- und Caching-Strategien, um Millionen von Dokumenten effizient zu verwalten.
Garantierte Qualität: Entwicklung von Evaluierungsmetriken & Dashboards, um hohe Relevanz, Recall und Systemstabilität zu messen und sicherzustellen.
Ich biete bewährte, unternehmensgerechte RAG-Lösungen, um dein Datenpotenzial freizusetzen.
Bist du bereit für ein zuverlässiges AI-Retrieval-System?
Kontaktiere mich, um dein Projekt zu besprechen!
Data Science and Blockchain Engineer with L2 Experience
Sprachen
Automatische Übersetzung
Automatische Übersetzung
Welche Technik verwendest du?
Ich werde verwenden: FAISS, Milvus, ChromaDB und jedes große LLM (GPT-4, Claude, Llama)
RAG gegen Fine-Tuning?
RAG ist besser für faktenbasierte, Echtzeit-Antworten und ist kosteneffizienter. Fine-Tuning ändert den Stil des Modells.
Welche Informationen benötigen Sie?
Dein Zugriff auf die Wissensbasis, Datenvolumen und der konkrete Anwendungsfall, den du aufbauen möchtest (z.B. Q&A-Chatbot).


