Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
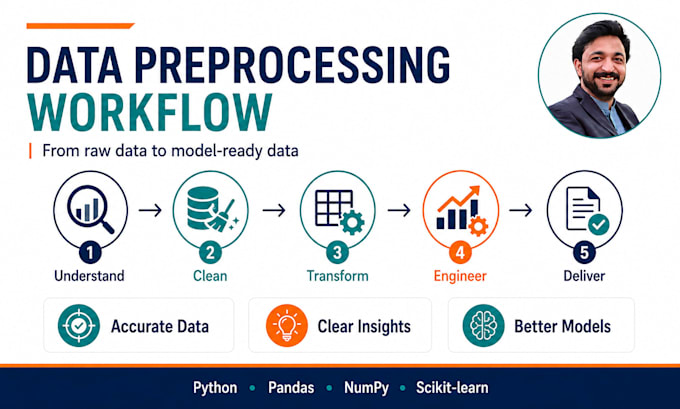
Arbeitest du mit unordentlichen, unvollständigen, unstrukturierten oder rohen Daten, die für Machine Learning, Forschung oder Geschäftsanalysen vorbereitet werden müssen? Ich werde dein Dataset mit Python und branchenüblichen Tools reinigen, vorverarbeiten, transformieren und in ein AI-fähiges Format bringen.
Meine Leistungen umfassen:
Du erhältst saubere, strukturierte Daten, wiederverwendbaren Python-Code und klare Dokumentation, je nach Paket.
Bitte kontaktiere mich vor der Bestellung, damit ich dein Dataset, deine Ziele, Dateiformat und Projektanforderungen prüfen kann.



Programmiersprache:
Python
•
SQL
•
Colab
•
NoSQL
•
MLflow
Frameworks:
scikit-learn
•
SimpleCV
•
keras
•
PyTorch
•
Panda
Tools:
Jupyter-Notizbuch
•
opencv
•
tensorflow
•
SimpleCV
•
CVAT
•
Colab
Automatische Übersetzung
Welche Arten von Datensätzen kannst du reinigen und vorverarbeiten?
Ich kann mit CSV, Excel, strukturierten Tabellen, Forschungsdatensätzen, Geschäftsdaten, Gesundheitsdaten, Umfragedaten, Prognosedaten und Machine Learning-Datensätzen arbeiten.
Was machst du bei der Datenvorverarbeitung?
Ich kann fehlende Werte, Duplikate, Ausreißer, ungültige Einträge, inkonsistente Formatierung, Kodierung, Skalierung, Normalisierung, Standardisierung und Daten-Transformationen handhaben.
Bietest du Feature Engineering an?
Ja. Ich kann neue bedeutungsvolle Features erstellen, wichtige Features auswählen, unnötige Features reduzieren und das Dataset für Machine Learning-Modelle vorbereiten.
Erhalte ich den Quellcode?
Ja, je nach Paket. Ich kann sauberen und wiederverwendbaren Python-Code mit Tools wie Pandas, NumPy, Scikit-learn und Jupyter Notebook bereitstellen.
Kannst du Explorative Datenanalyse durchführen?
Ja. Ich kann EDA inklusive Zusammenfassungsstatistiken, Verteilungsanalysen, Korrelationsanalysen, Visualisierungen und wichtige Erkenntnisse aus deinem Dataset liefern.
Kannst du Daten für Machine Learning Modelle vorbereiten?
Ja. Ich kann ein AI-fähiges Dataset für Klassifikation, Regression, Clustering, Prognosen oder Deep-Learning-Projekte vorbereiten.
Arbeitest du an Forschungs- oder Abschlussdatensätzen?
Ja. Ich kann bei der Vorbereitung von Abschlussarbeiten, Veröffentlichungen, akademischen, Gesundheits-, EEG/BCI- und Forschungs-Datensätzen helfen.
Q8: Was benötigst du von mir, bevor du anfängst?
Bitte teile dein Dataset, dein Projektziel, falls vorhanden die Zielspalte, das gewünschte Ausgabeformat sowie spezifische Vorverarbeitungs- oder Feature-Engineering-Anforderungen.
Q9: Kannst du in diesem Gig ein Machine Learning-Modell bauen?
Dieser Gig konzentriert sich hauptsächlich auf Datenvorverarbeitung und Feature Engineering. Wenn du Modellentwicklung brauchst, kann ich das als Zusatzservice oder in einem separaten ML-Gig anbieten.
Q10: Soll ich dich vor der Bestellung kontaktieren?
Ja, bitte kontaktiere mich zuerst, damit ich dein Dataset prüfen, deine Anforderungen verstehen und das beste Paket empfehlen kann.