Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Systeme und ML-Projekte in C Python SQL pünktlich und optimiert
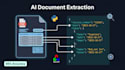
Stehst du vor einer Flut von PDFs, Rechnungen, Formularen oder gescannten Bildern, aus denen Daten extrahiert werden müssen? Ich entwickle produktionsreife KI-Systeme, die das automatisch erledigen.
Ich bin ein KI- und Computer-Vision-Ingenieur mit praktischer Erfahrung im Aufbau von End-to-End-Deep-Learning-Pipelines, von Rohdaten bis zu einer funktionierenden, einsatzbereiten Lösung, die du tatsächlich nutzen kannst.
WAS ICH BAUE
Intelligente Dokumentenverarbeitung (IDP)
Strukturierte Daten aus Rechnungen, Quittungen, Verträgen, medizinischen Formularen, Steuerdokumenten und jedem benutzerdefinierten PDF- oder Bildformat extrahieren.
Maßgeschneiderte OCR-Pipelines
Über die einfache OCR hinaus entwickle ich KI-Systeme, die Layout, Tabellen, Kontrollkästchen und Handschrift mit TesseractOCR, PaddleOCR und Deep Learning verstehen.
️ Computer Vision & Objekterkennung
Maßgeschneiderte YOLO (v8/v11)-Modelle, Bildklassifikation, Segmentierung und Objekterkennung, trainiert auf deinem eigenen Datensatz.
KI/ML-Modellentwicklung
CNN, RNN, LSTM für Klassifikation, Regression, NLP-Textextraktion und Zeitreihenprognosen.
Modellbereitstellung & API
REST API mit FastAPI oder Flask, Docker-Containerisierung, Cloud-Deployment (AWS, GCP), Integration in dein Frontend.
TOOLS & STACK
Python, PyTorch, TensorFlow, OpenCV, YOLO, PaddleOCR, Tesseract

Automatische Übersetzung
Muss ich Trainingsdaten bereitstellen?
Das hängt vom Projekt ab. Für gängige Dokumententypen wie Rechnungen oder Quittungen kann ich vortrainierte Modelle verwenden und an dein Format anpassen. Für hochgradig individuelle Dokumente oder proprietäre Layouts ist ein Beispiel-Datensatz mit 50–200 Beispielen ideal. Falls du keinen hast, kann ich dir zeigen, wie du welche sammelst und
In welchem Format werden die extrahierten Daten geliefert?
Standardmäßig liefere ich strukturierte JSON- oder CSV-Ausgaben. Wenn du sie in einer Datenbank, Excel-Datei oder via API in dein bestehendes System einspeisen möchtest, ist das möglich — erwähne es einfach, wenn du mir schreibst.
Wie genau wird die Extraktion sein?
Die Genauigkeit hängt von der Qualität und Komplexität des Dokuments ab. Bei sauberen, digitalen PDFs liegt sie typischerweise bei 95–99 %. Bei gescannten oder handgeschriebenen Dokumenten sind 85–95 % realistisch. Ich teste immer an deinen tatsächlichen Dokumenten vor der Lieferung und füge einen Leistungsbericht bei.
Können Sie mit Dokumenten in anderen Sprachen als Englisch arbeiten?
Ja. PaddleOCR unterstützt über 80 Sprachen, und ich habe Erfahrung mit mehrsprachigen Pipelines. Bitte nenne deine Sprache, wenn du mich kontaktierst.
Werde ich der Eigentümer des Codes sein?
Ja, 100 %. Alle Quellcodes, Modelgewichte und Dokumentationen gehören dir. Ich behalte keine Rechte an dem, was ich für dich entwickle.


