Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD





Automatische Übersetzung
Hast du genug von manueller Dokumentenverarbeitung? Lass KI das in Sekunden erledigen.
Ich entwickle eine maßgeschneiderte OCR- und Document Intelligence-Pipeline, die Text aus PDFs, gescannten Dateien, handschriftlichen Blättern und Bildern extrahiert, verarbeitet und analysiert und dabei saubere, strukturierte, produktionsbereite Ergebnisse liefert.
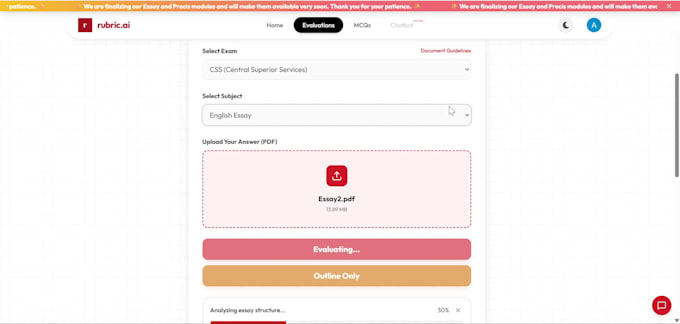
Ich habe echte OCR-Systeme wie Rubric Ai gebaut und eingesetzt, inklusive einer KI-gestützten Prüfungsbewertungsplattform und einer automatisierten Rechnungsverarbeitungs-Pipeline mit echten Nutzern, keine Nebenprojekte.
Was ich baue: OCR-Pipeline für PDFs, Bilder & gescannte Dokumente Vorverarbeitung für rauschhafte, handschriftliche & minderwertige Eingaben LLM-gestützte Analyse & intelligente Textextraktion Automatisierte Annotation & Bewertungs-Engine Strukturierte JSON/CSV-Ausgabe, bereit für die Integration FastAPI-Backend & Datenbankintegration
Perfekt für: Rechtliche, medizinische & finanzielle Dokumentenverarbeitung Prüfungs-, Bewertungs- & Notenautomatisierung Rechnungs-, Quittungs- & Vertragsdatenextraktion
Warum du mich wählen solltest: Echte eingesetzte OCR-Systeme, keine Tutorials Handhabung von Handschrift, Mischsprachen & schlechten Scans Sauberer Code, vollständiger Quellcode inklusive, pünktliche Lieferung
Schreib mir eine Nachricht und wir klären dein Projekt, bevor du bestellst.
Ai and Computer vision Solutions
Sprachen
Automatische Übersetzung
Automatische Übersetzung
Kannst du ein individuelles Dokumentenbewertungs- oder Notensystem bauen?
Absolut. Ich habe rubric-basierte LLM-Bewertungssysteme entwickelt, die Dokumente Abschnitt für Abschnitt bewerten und annotieren. Ob Prüfungsbewertung, Vertragsprüfung oder Formularvalidierung – ich kann eine intelligente Bewertungs-Pipeline nach deinen Kriterien erstellen.
Welche Dokumententypen kann deine OCR-Pipeline verarbeiten?
Meine OCR-Pipeline verarbeitet PDFs, gescannte Bilder, fotografierte Dokumente und handschriftliche Blätter. Sie funktioniert auch mit minderwertigen Scans, mehrsprachigem Inhalt und rauschhaften Eingaben; Vorverarbeitung ist inklusive, um jedes Mal sauberen, genauen Text zu extrahieren.
Kannst du das OCR-System in meine bestehende Anwendung oder Datenbank integrieren?
Ja. Ich baue FastAPI REST-Backends, die direkt mit deiner bestehenden Anwendung verbunden werden. Ich unterstütze MongoDB und PostgreSQL für strukturierte Datenspeicherung und liefere sauberen JSON- oder CSV-Ausgabe, die mit jedem nachgelagerten System kompatibel ist.
Was ist Dokumenten-Intelligenz und wie unterscheidet sie sich vom einfachen OCR?
Einfaches OCR extrahiert nur Text. Dokumenten-Intelligenz geht weiter — mit LLMs, um den extrahierten Inhalt zu analysieren, zu klassifizieren, zu annotieren und anhand definierter Kriterien zu bewerten. Es ist der Unterschied zwischen Dokument lesen und es wirklich verstehen.
Stellst du Quellcode und Dokumentation bereit?
Ja, jede Lieferung enthält vollständigen Quellcode, detaillierte Inline-Kommentare und Setup-Dokumentation, damit dein Team das System eigenständig warten und erweitern kann, ohne auf mich angewiesen zu sein.
Wie lange dauert es, eine vollständige Dokumenten-Intelligenz-Pipeline zu bauen?
Eine einfache OCR-Extraktionspipeline dauert 3 Tage. Ein vollständiges Dokumenten-Intelligenz-System mit LLM-Analyse, Annotation-Engine, API und Datenbankintegration braucht in der Regel 7-10 Tage, abhängig von der Komplexität. Schreib mir zuerst, um eine genaue Zeitschätzung für dein Projekt zu bekommen.