Professionelle Data Engineering Services | ETL Pipelines | AWS | Databricks
Suchst du nach skalierbaren, zuverlässigen Datenpipelines für dein Business?
Ich bin ein Data Engineer mit über 6 Jahren Erfahrung in der Entwicklung und Optimierung von ETL-Pipelines mit modernen Cloud- und Big Data-Technologien.
Was ich für dich tun kann:
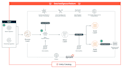
- Aufbau von End-to-End ETL-Pipelines (Extract, Transform, Load)
- Entwicklung von PySpark / Spark-Jobs für groß angelegte Datenverarbeitung
- Design von Data Lakes auf AWS S3
- Erstellung von Workflows mit Apache Airflow
- Implementierung von Databricks-Lösungen für Analytics und ML
- Optimierung der Pipelines für Performance und Kosteneffizienz
- Integration von Daten aus APIs, Datenbanken und Dateien (CSV, JSON, Parquet)
️ Tech Stack:
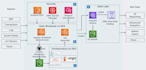
- AWS: S3, Glue, IAM, CloudWatch
- Databricks
- Apache Spark / PySpark
- Apache Airflow
- Python / SQL
Warum mich wählen?
- Habe Pipelines gebaut, die Multi-Terabyte-Datasets verarbeiten
- Starker Fokus auf Performance-Optimierung
- Sauberer, wartbarer, produktionsreifer Code
- Schnelle Kommunikation & zuverlässige Lieferung
Beispielhafte Anwendungsfälle:
- Datenlager-Pipelines
- Datenlake-Architektur
- Batch- & geplante Workflows
- Datenbereinigung & Transformation
- API-zu-S3-Ingestion-Pipelines