Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Daten in Erkenntnisse verwandeln und Ideen in beeindruckende Web-Lösungen umsetzen
Suchst du einen erstklassigen Data Engineering Experten, der deine Big Data Herausforderungen in nahtlose, skalierbare Lösungen verwandelt?
Willkommen! Ich bin Nitin, ein erfahrener Big Data Engineer mit über 3 Jahren Erfahrung und tiefgehender Expertise in modernen Data Engineering Technologien.
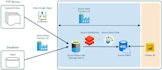
Ich spezialisiere mich auf die Erstellung robuster, zuverlässiger und effizienter Datenpipelines mit Databricks, Apache Spark, Apache Airflow, Azure Data Factory (ADF) und ereignisgesteuerten Architekturen mit Kafka. Ob klassische ETL/ELT-Workflows, fortschrittliche Data Warehousing-Lösungen oder innovative Lakehouse-Architekturen mit Delta Lake – ich bin für dich da.
Was ich anbiete:
Lass uns zusammenarbeiten, um den wahren Wert deiner Daten freizusetzen



Automatische Übersetzung
Bieten Sie auch nach dem Projekt Unterstützung an?
Ja, ich biete Support nach Projektabschluss und Fehlerbehebung, um einen reibungslosen Betrieb zu gewährleisten.
Wie lange dauert die Lieferung?
Die Lieferzeit hängt von der Komplexität des Projekts ab, aber ich bemühe mich stets, qualitativ hochwertige Arbeit so schnell wie möglich zu liefern und eine klare Kommunikation zu pflegen.
Können Sie bei der Leistungsoptimierung helfen?
Absolut! Ich analysiere und optimiere deine bestehenden Daten-Workflows, um maximale Leistung bei minimalen Kosten zu gewährleisten.
Auf welche Technologien sind Sie spezialisiert?
Databricks, Apache Spark, Apache Airflow, Azure Data Factory, Kafka, MQTT, Delta Lake, PySpark, SQL und modernes Data Warehousing.
Welche Art von Projekten können Sie abwickeln?
Von der Erstellung skalierbarer ETL/ELT-Pipelines bis hin zur Verwaltung von Echtzeit-Streaming-Daten und der Gestaltung von Data Warehouse-Architekturen – ich betreue Projekte jeder Größenordnung, von Startups bis hin zu Unternehmenssystemen.


