Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
KI ML Ingenieur
Deine Daten haben Antworten.
Die Frage ist, ob dein Modell sie tatsächlich findet.
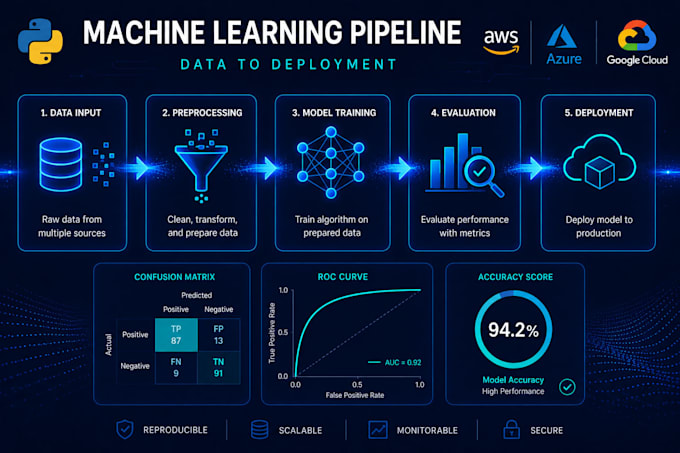
Die meisten Machine-Learning-Projekte scheitern nicht wegen schlechter Daten, sondern wegen schlechter Vorverarbeitung, falscher Algorithmuswahl und Modellen, die nie in Betrieb genommen werden. Ich entwickle End-to-End-ML-Lösungen, die vom Rohdateninput bis zum funktionierenden, dokumentierten, produktionsbereiten Modell reichen.
Was du bekommst:
Ich habe Modelle entwickelt, die Millionen von Datensätzen in Bereichen wie Finanzen, E-Commerce und Betrieb verarbeiten, unter Verwendung von Python, XGBoost, LightGBM, scikit-learn und mehr.
Du bist dir unsicher, was deine Daten brauchen? Schreib mir vor der Bestellung. Ich sage dir genau, welcher Ansatz zu deinem Problem passt.


Programmiersprache:
Python
•
Colab
•
MLflow
Frameworks:
scikit-learn
•
Google ML Kit
•
keras
•
PyTorch
•
Panda
Tools:
Jupyter-Notizbuch
•
opencv
•
tensorflow
•
MLflow
•
Colab
Automatische Übersetzung
Welche Informationen muss ich angeben, um loszulegen?
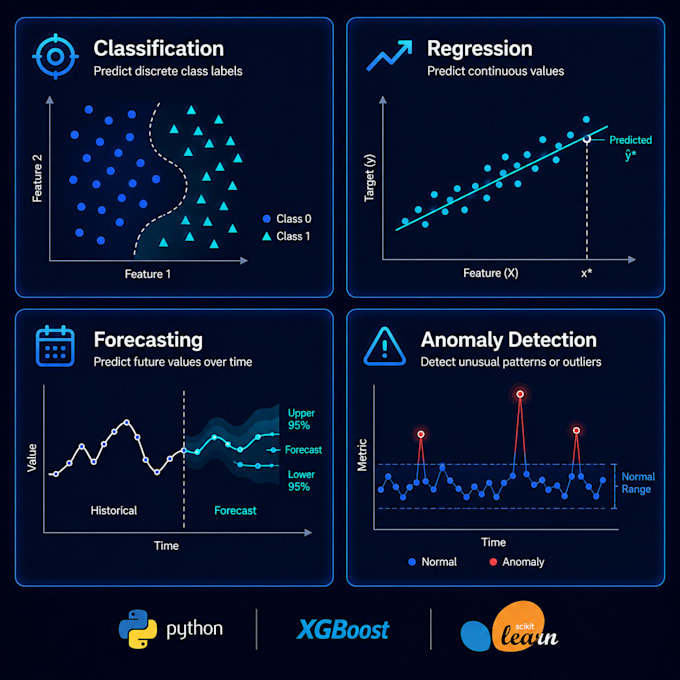
Teile einfach deinen Datensatz und sag mir, welches Ergebnis du vorhersagen oder klassifizieren möchtest. Wenn du spezielle Geschäftsanforderungen, Genauigkeitsziele oder Einschränkungen wie Speicher oder Geschwindigkeit hast, erwähne diese ebenfalls. Je mehr Kontext du gibst, desto besser kann ich das Modell für dich bauen.
Welche Dateiformate akzeptieren Sie für Daten?
Ich arbeite mit CSV, Excel, JSON, SQL-Datenbanken und den gängigsten Datenformaten. Wenn deine Daten woanders gespeichert sind, schreib mir zuerst und wir finden die beste Lösung dafür.
Mein Datensatz ist sehr klein. Kannst du trotzdem ein Modell bauen?
Ja, aber die Vorgehensweise ändert sich je nach Größe. Für kleinere Datensätze nutze ich Techniken wie Cross-Validation, Regularisierung und einfachere Modelle, die besser generalisieren. Ich sage dir immer ehrlich, wenn deine Daten zu begrenzt sind, um zuverlässige Ergebnisse zu liefern.
Werde ich das Modell nutzen können, ohne Python zu kennen?
Wenn du das Standard- oder Premium-Paket buchst, stelle ich eine vollständige Dokumentation bereit, die erklärt, wie alles funktioniert. Beim Premium-Paket bekommst du außerdem eine REST-API, mit der du Daten an das Modell senden und Vorhersagen aus jeder Anwendung heraus erhalten kannst, ohne Code zu berühren.
Was, wenn die Genauigkeit des Modells nicht ausreicht?
Vor Beginn setze ich realistische Erwartungen basierend auf deinen Daten. Wenn die Ergebnisse nicht den vereinbarten Standards entsprechen, arbeite ich mit Revisionen an der Verbesserung der Leistung. Ich liefere nicht nur ab und verschwindet.
Unterschreibst du NDAs oder behandelst meine Daten vertraulich?
Ja. Deine Daten und Geschäftsinformationen werden streng vertraulich behandelt. Wenn du eine formelle NDA unterschreiben möchtest, bevor du Daten teilst, mache ich das gern.
Kannst du mit unausgeglichenen Datensätzen oder unordentlichen realen Daten arbeiten?
Das ist der Großteil dessen, was echtes ML im Alltag ausmacht. Ich behandle Klassenungleichgewicht mit Techniken wie SMOTE und Klassengewichtung und gehe mit fehlenden Werten, Ausreißern und inkonsistenten Formaten im Schritt der Vorverarbeitung um.
Auf welchen Cloud-Plattformen deployst du?
Ich arbeite hauptsächlich mit Azure, GCP und AWS. Wenn du eine Präferenz hast oder bereits eine Plattform nutzt, sag mir Bescheid und ich setze es dort um. Cloud-Deployment ist im Premium-Paket enthalten und als Add-on für andere Pakete verfügbar.