Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Ich mache Data Science oder Datenanalyse
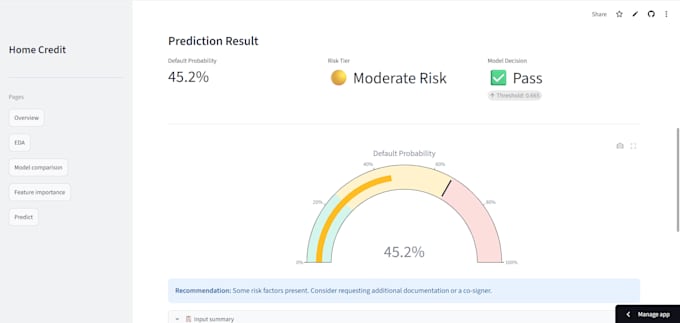
Live Demo: credit-risk-prediction-better.streamlit.app
GitHub: github.com/Niqar/Credit-risk-prediction
Hast du Rohdaten, weißt aber nicht, wie du sie in ein funktionierendes ML-Modell umwandeln kannst? Ich erstelle dir eine komplette, produktionsbereite Machine-Learning-Pipeline, die aus unordentlichen Daten ein Modell macht, das tatsächlich funktioniert.
Was ich liefere:
Datenbereinigung & Feature Engineering (Umgang mit fehlenden Werten, Kodierung, Skalierung)
Modeltraining mit LightGBM, XGBoost, Random Forest oder Logistic Regression
Hyperparameter-Optimierung mit Optuna für beste Leistung
Vollständiger Bewertungsbericht (AUC, F1-Score, Precision, Recall, Confusion Matrix)
Saubere scikit-learn Pipeline, reproduzierbar & einsatzbereit
Jupyter Notebook + dokumentierter Python-Code
GitHub-Repository (auf Anfrage)
Warum mit mir arbeiten:
Ich trainiere nicht nur ein Modell und übergebe es. Ich dokumentiere jeden Schritt, damit du verstehst, was gemacht wurde und warum, und sorge dafür, dass die Pipeline sauber genug ist, um sie wiederzuverwenden oder zu erweitern.
Schau dir mein Portfolio an: credit-risk-prediction-better.streamlit.app
Fühl dich frei, mich vor der Bestellung zu kontaktieren. Ich werde deinen Datensatz prüfen und bestätigen, dass ich helfen kann.



Programmiersprache:
Python
•
SQL
Frameworks:
scikit-learn
•
keras
•
PyTorch
Tools:
Jupyter-Notizbuch
•
opencv
•
tensorflow
•
Excel
•
Colab
Automatische Übersetzung
Mit welcher Art von Daten arbeiten Sie?
Ich arbeite mit strukturierten/tabellarischen Daten — CSV, Excel oder SQL-Exporte. Das umfasst Klassifikationsprobleme (Betrug, Churn, Kreditrisiko) und Regressionsprobleme (Preisschätzung, Verkaufsprognose). Für Bild- oder Textdaten schick mir bitte zuerst eine Nachricht, damit ich den Umfang einschätzen kann.
Was, wenn mein Datensatz unordentlich ist oder fehlende Werte hat?
Das ist ganz normal — mit unordentlichen Daten umzugehen, gehört zu meinem Job. Ich bereinige sie, behandle fehlende Werte, kodieren kategoriale Features und skaliere numerische als Teil jedes Pakets.
Welche Machine-Learning-Modelle verwenden Sie?
Hauptsächlich LightGBM, XGBoost, Random Forest und Logistic Regression — je nach deinen Daten und Zielen. In den Standard- und Premium-Paketen trainiere und vergleiche ich mehrere Modelle, damit du das beste Ergebnis bekommst.
Kann ich den Code selbst wiederverwenden oder anpassen?
Ja. Der gesamte Code ist sauber, kommentiert und als richtige scikit-learn Pipeline strukturiert — so kannst du ihn leicht mit neuen Daten neu trainieren oder Parameter anpassen. Ich erkläre dir auch die wichtigsten Teile, damit du nicht im Dunkeln tappst.