Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Intelligente AI-Web-Apps und NLP-Lösungen für Daten entwickeln
Titel: Automatisierte Dokumentenorganisation & NLP-Analyse
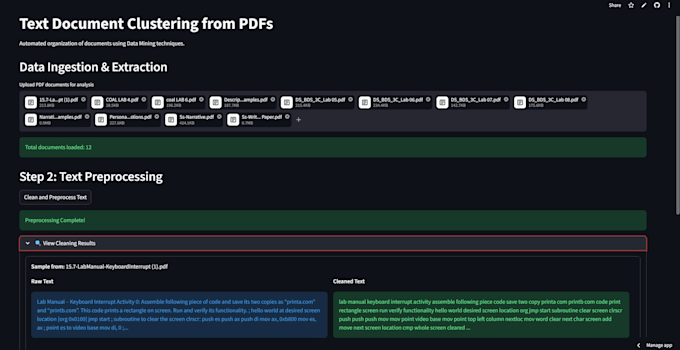
Hallo! Wenn du von einem riesigen Haufen PDF-Dokumente überwältigt bist, kann ich dir helfen, sie mit KI-gestützter NLP zu organisieren.
Ich gruppiere die Dateien nicht nur nach einfachen Schlüsselwörtern. Ich nutze fortschrittliche semantische Einbettungen, um die tatsächliche Bedeutung deines Textes zu verstehen, damit deine Dokumente logisch und präzise kategorisiert werden.
Was ich anbiete:
Ich lege Wert auf Genauigkeit und sauberen Code. Schreib mir heute, um dein Projekt zu besprechen!




Programmiersprache:
Python
Frameworks:
scikit-learn
•
Panda
Tools:
Jupyter-Notizbuch
•
Colab
Automatische Übersetzung
Welche Art von PDF-Dokumenten kannst du verarbeiten?
Ich kann fast alle textbasierten PDFs verarbeiten, inklusive Forschungsarbeiten, Geschäftsberichte und Artikel.
Kannst du auch Microsoft Word (.docx)-Dateien verarbeiten?
Ja, absolut! Während die Standardversion meines Tools für PDFs optimiert ist, kann ich die Datenaufnahme-Pipeline leicht anpassen, um .docx- und .doc-Dateien zu verarbeiten.
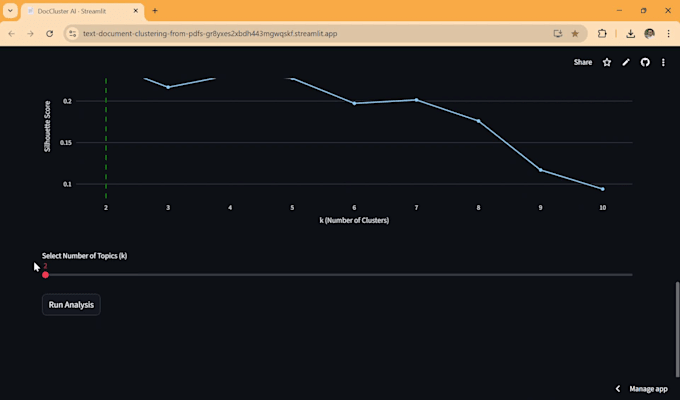
Wie stellst du sicher, dass die Cluster genau sind?
Ich verwende eine "Silhouette Score"-Analyse, um mathematisch die logischste Anzahl an Gruppen für deine Daten zu bestimmen. So sind die Cluster nicht nur zufällig, sondern basieren auf tatsächlicher semantischer Dichte.
Muss ich die "Themen" vorher angeben?
Nein! Das ist "Unsupervised Learning", was bedeutet, dass die KI die Muster erkennt und die Dokumente selbst gruppiert.
Sind meine Daten sicher?
Auf jeden Fall. Ich verarbeite deine Daten lokal in meiner sicheren Entwicklungsumgebung. Sobald das Projekt geliefert und akzeptiert ist, lösche ich deine Dokumente aus meinem System, es sei denn, du verlangst etwas anderes.
Kann ich das Streamlit-Dashboard auf meinem eigenen Computer laufen lassen?
Ja. Wenn du das Premium-Paket wählst, stelle ich eine requirements.txt-Datei und eine .devcontainer-Konfiguration bereit, damit du die App lokal in VS Code ausführen oder in die Cloud deployen kannst.