Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Mit harter Arbeit und Mühe können Sie alles erreichen
Suchst du einen technischen Experten, der deine Cloud-Infrastruktur plant und leistungsstarke ETL/ELT-Pipelines entwickelt? Dann bist du hier genau richtig.
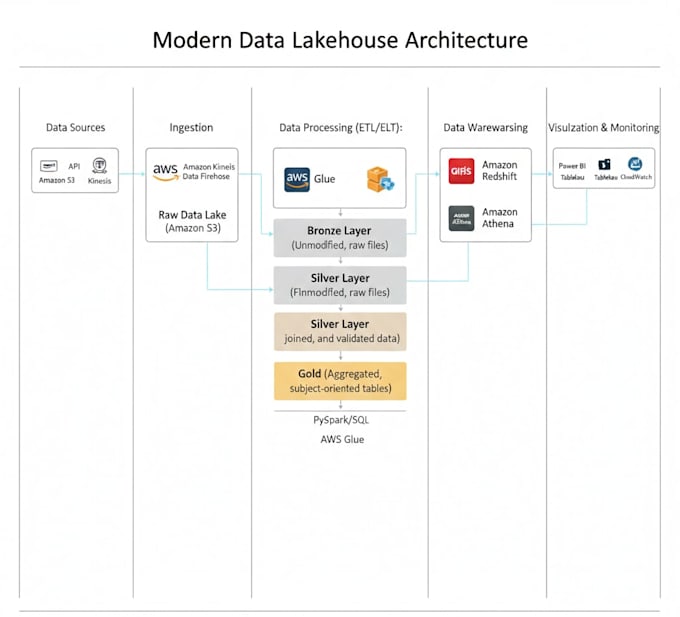
Ich spezialisiere mich auf das Design und die Implementierung von End-to-End-Datenlösungen. Ob du ein modernes Data Lakehouse auf Azure brauchst, eine robuste Pipeline auf AWS oder komplexe Transformationen in Databricks – ich liefere produktionsfertige Architekturen.
Meine Expertise & Services:
Der Tech-Stack:

Expertise:
API-Integration
•
Big Data
•
Datenextraktion
•
etl
•
SQL
•
NoSQL
Automatische Übersetzung
Können Sie auch die Implementierungsarchitektur erläutern?
Ja, ich biete eine vollständige Übersicht über die Architektur. Ich erkläre den Datenfluss, die Auswahl der spezifischen Cloud-Services (ADF, Databricks usw.) und die Überlegungen hinter dem Design, damit dein Team es künftig verwalten kann.
Kannst du sowohl kleine als auch große Datenprojekte umsetzen?
Absolut. Ich entwerfe Pipelines mit Blick auf Skalierbarkeit. Ob du eine einfache API-zu-SQL-Ingestion für ein Startup brauchst oder eine große Organisation, die Milliarden von Zeilen mit Spark verarbeitet – ich passe Rechenleistung und Speicher an dein Volumen und Budget an.
Stellst du technische Dokumentation bei der Lieferung bereit?
Jedes Projekt beinhaltet eine technische Übersicht und eine Setup-Anleitung. Für detaillierte Dokumentation auf Unternehmensebene (inklusive Datenwörterbücher und Mappings) erwähne dies bitte während unseres Discovery-Calls, damit ich es in den Projektumfang aufnehmen kann.
Bietest du laufenden Support für die Lösungen, die du entwickelst?
Ja. Ich biete Support nach der Lieferung, um sicherzustellen, dass die Pipeline reibungslos in Produktion läuft. Das umfasst Fehlerbehebung bei ersten Läufen, Bugfixes und Performance-Optimierung. Langfristige Wartung oder monatlicher Support sind ebenfalls möglich.
Wie bestimmst du die Preise für ein Projekt?
Die Preisgestaltung basiert auf drei Faktoren: der Anzahl der Datenquellen, der Komplexität der Transformationen (ETL/ELT-Logik) und den Orchestrierungsanforderungen. Nach Prüfung deines Datenschemas und deiner Projektziele erstelle ich ein transparentes Angebot.
Wie gehst du bei einem Projektstart vor?
Wir beginnen mit einer kurzen Discovery-Phase, in der ich deine Datenquellen und Zielanforderungen prüfe. Sobald die Architektur genehmigt ist, richte ich die Umgebung ein, baue die Pipelines, führe gründliche Datenvalidierungen durch und übergebe schließlich den Code mit einer technischen Einführung.