Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Ich verwandle Daten in Intelligenz mit Machine Learning und Deep Learning
Suchst du nach genauen, produktionsreifen ML-Modellen, die echte Probleme lösen? Du bist hier genau richtig.
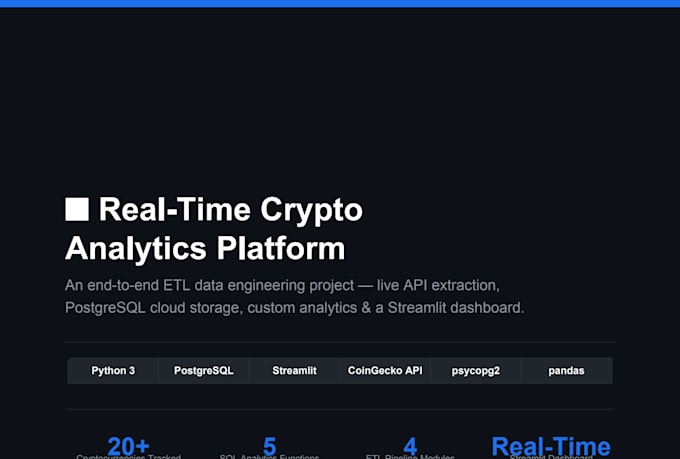
Ich entwickle End-to-End-Lösungen im Maschinenlernen und Deep Learning in Python, von rohen, unordentlichen Daten bis hin zu voll funktionsfähigen Vorhersagemodellen und Datenpipelines.
WAS DU BEKOMMST
BEZAHLTE PROJEKTE
Sauberer Code. Klare Erklärungen. Echte Ergebnisse.
Schreib mir vor der Bestellung, um dein Projekt zu besprechen!

Programmiersprache:
Python
•
SQL
Frameworks:
scikit-learn
•
keras
APIs:
Andere
Tools:
Jupyter-Notizbuch
•
tensorflow
•
Excel
•
MLflow
•
Colab
Automatische Übersetzung
Welche ML-Probleme kannst du lösen?
Ich kann eine Vielzahl von überwachten und unüberwachten ML-Problemen lösen, einschließlich Regression (Preisschätzung, Verkaufsprognose), Klassifikation (Spam-Erkennung, Churn-Vorhersage usw.), Clustering und Anomalieerkennung. Wenn du unsicher bist, ob dein Problem passt, schreib mir einfach und ich sage dir Bescheid.
Muss ich meinen eigenen Datensatz bereitstellen?
Ja, idealerweise solltest du deinen Datensatz bereitstellen. Falls du keinen hast, kann ich einen relevanten öffentlichen Datensatz (von Kaggle, UCI oder offenen APIs) für dein Problem beschaffen. Je besser deine Daten, desto genauer dein Modell – also ist das Teilen echter Daten immer die beste Wahl.
In welchem Format werden die Ergebnisse vorliegen?
Du erhältst ein sauberes Jupyter Notebook (.ipynb) mit vollständigem Quellcode, gut kommentierten Erklärungen und Visualisierungen. Bei Standard- und Premium-Paketen bekommst du außerdem einen PDF-Bericht oder eine Modell-Dokumentation. Alle Dateien werden als ZIP-Archiv geliefert, damit alles organisiert und einsatzbereit ist.
Kannst du eine bestimmte Modellgenauigkeit garantieren?
Kein ehrlicher ML-Experte kann eine feste Genauigkeit garantieren, da diese stark von der Datenqualität, -größe und der Komplexität des Problems abhängt. Was ich garantieren kann, ist, dass ich die besten Vorverarbeitungs-, Feature-Engineering- und Modelloptimierungstechniken anwende, um die Leistung zu maximieren. Ich zeige dir immer die Evaluierungsmetrik.
Welche Python-Bibliotheken und Tools verwendest du?
Ich nutze hauptsächlich scikit-learn, Pandas, NumPy, Matplotlib und Seaborn für ML und Datenanalyse. Für Pipelines und Datenbanken verwende ich PostgreSQL, psycopg2 und MySQL. Für Dashboards nutze ich Streamlit. Für Deep-Learning-Aufgaben setze ich TensorFlow/Keras ein. Alle Bibliotheken sind Industriestandard und weit verbreitet.
Verstehe ich den Code auch, wenn ich kein Technik-Experte bin?
Absolut. Jedes Notebook ist mit klaren, schrittweisen Kommentaren versehen, die erklären, was jeder Codeblock macht und warum. Bei Standard- und Premium-Paketen füge ich außerdem eine schriftliche Zusammenfassung der Erkenntnisse und Ergebnisse in einfachem Englisch bei, damit du die Einsichten verstehst, nicht nur den Code.
Kannst du das Modell bereitstellen, damit ich es live nutzen kann?
Ja, Cloud-Deployment und API-Integration sind im Premium-Paket enthalten. Ich kann dein Modell als Streamlit-Web-App oder REST-API-Endpunkt bereitstellen, damit es einsatzbereit ist. Wenn du es auf einer bestimmten Plattform (AWS, Render) deployen möchtest, schreib mir vor der Bestellung, damit wir die Einrichtung abstimmen können.
Was, wenn ich etwas Individuelles brauche, das nicht in deinen Paketen aufgeführt ist?
Kein Problem. Schreib mir mit deinen Anforderungen, und ich sende dir ein individuelles Angebot, das genau auf deine Bedürfnisse zugeschnitten ist. Ob es sich um einen einzigartigen Datensatz, einen speziellen Algorithmus, eine größere Pipeline oder ein kombiniertes ML + Dashboard-Projekt handelt – ich freue mich auf die Diskussion und ein Angebot.
Werden meine Daten vertraulich behandelt?
100 % ja. Deine Daten werden ausschließlich zur Erfüllung deines Projekts verwendet und niemals geteilt, veröffentlicht oder in irgendeiner Form wiederverwendet. Wenn du vor der Weitergabe sensibler Daten eine Geheimhaltungsvereinbarung (NDA) benötigst, unterschreibe ich diese gern. Dein Datenschutz und die Datensicherheit werden bei jedem Projekt ernst genommen.
Wie funktionieren Revisionen?
Basic umfasst 1 Revision, Standard 2 und Premium 3. Eine Revision umfasst Anpassungen am bestehenden Umfang, wie das Feinjustieren von Modellparametern, Ändern von Visualisierungen oder Beheben von Fehlern. Es beinhaltet keine vollständige Ergänzung neuer Features oder Algorithmen außerhalb des vereinbarten Umfangs.