Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
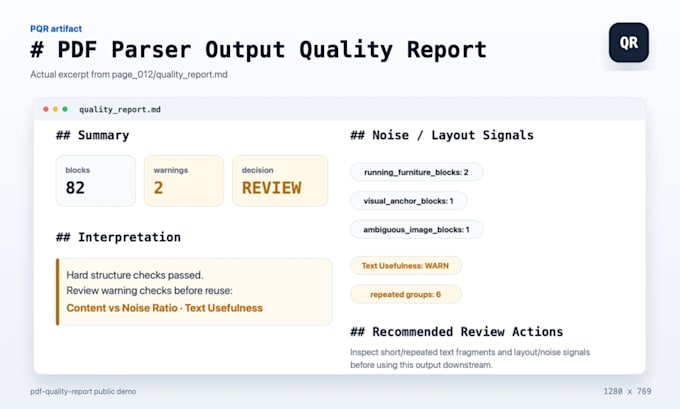
PDF zu JSON und Markdown Ausgabe Review
Dein PDF-Extraktionsergebnis sieht brauchbar aus, aber du brauchst es vor der Überprüfung, Bereinigung, Schema-Mapping oder RAG-Ingestion-Vorbereitung noch gereinigt und geprüft?
Ich überprüfe bestehende Parser-Ausgaben von Docling, PyMuPDF, Unstructured oder ähnlichen Tools und erstelle:
Die Arbeit beginnt bei deinem Ziel: Welche Felder wichtig sind, welche IDs oder Quellenreferenzen erhalten bleiben müssen und wie du die Ausgabe downstream verwenden willst.
Was ich brauche:
Was ich nicht abdecke:

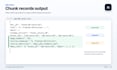
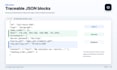
Technologie:
Python
Automatische Übersetzung
Mit welchen Parser-Formaten kannst du arbeiten?
Am besten passt Docling JSON. PyMuPDF, Unstructured, LlamaParse oder ähnliches JSON-/Dict-Format-Parser-Output kann nach einer schnellen Musterprüfung ebenfalls funktionieren.
Bietest du OCR oder Tabellenerstellung an?
Standardmäßig nicht. Dieser Service ist für die Überprüfung und Bereinigung bestehender Parser-Ausgaben. Gescannte Dokumente, OCR-Bereinigung und komplexe Tabellenerstellung benötigen einen individuellen Umfang nach einer Musterprüfung.
Ist das ein RAG-Systemaufbau?
Nein. Ich kann überprüfbare JSON-, Markdown- oder JSONL-Datensätze für die Ingestionsvorbereitung bereitstellen, aber ich baue keinen Chatbot, kein Retrieval-System, keine Vektordatenbank oder Bewertungs-Tools für die Antwortqualität.