Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Bioinformatik-Pipeline-Entwickler
Hast du gelabelte Genexpressionsdaten und brauchst
einen Machine-Learning-Klassifikator, um Krebs-
Subtypen oder Patientenergebnisse vorherzusagen?
Ich erstelle eine komplette ML-klassifikationspipeline
maßgeschneidert für dein Genom-Datensatz.
WAS DU BEKOMMST:
- Datenvorverarbeitung und Normalisierung
- Merkmalsauswahl, um die informativsten Gene zu identifizieren
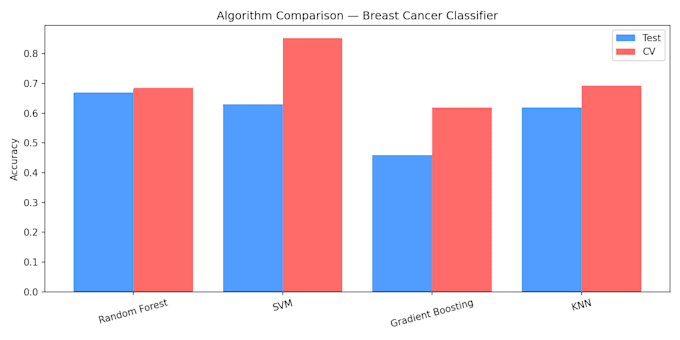
- Vergleich verschiedener Algorithmen (Random Forest, SVM,
Gradient Boosting, KNN)
- Kreuzvalidierungsgenauigkeit
- Verwirrungsmatrix und Klassifikationsbericht
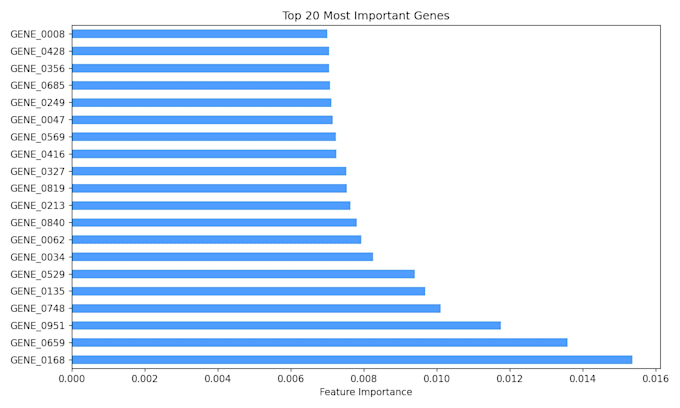
- Visualisierung der Feature-Importance
- Produktionsfertiges, gespeichertes Modell
MEINE ERFAHRUNG:
Ich habe einen Brustkrebs-Subtyp-Klassifikator auf Genexpressionsdaten erstellt, der eine
Kreuzvalidierungsgenauigkeit von 85,2 % mit SVM erreicht hat. Es wurden 4 Subtypen klassifiziert:
LuminalA, LuminalB, HER2, TripleNegative.
Vollständige Pipeline auf GitHub.
WAS ICH VON DIR BRAUCHE:
- Genexpressionsmatrix (Proben x Gene)
- Subtyp- oder Outcome-Labels für jede Probe
- Anzahl der zu prognostizierenden Klassen
- Bekannte wichtige Gene oder Wege
TOOLS: Python, scikit-learn, Pandas, numpy,
matplotlib, seaborn, joblib, Linux, Git



Expertise:
Klassifizierung
•
Clustering
•
Prädiktive Analyse
Programmiersprache:
Python
•
R
Frameworks:
scikit-learn
•
Panda
APIs:
Andere
Tools:
Jupyter-Notizbuch
•
RStudio