Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Datenautomatisierungsarchitekt und ETL-Spezialist
Dateninfrastruktur & Analytik
Ich baue ETL/ELT-Systeme, die fragmentierte Daten in zuverlässige Assets verwandeln. Fokus: Stabilität und Skalierbarkeit statt kurzfristiger Lösungen.
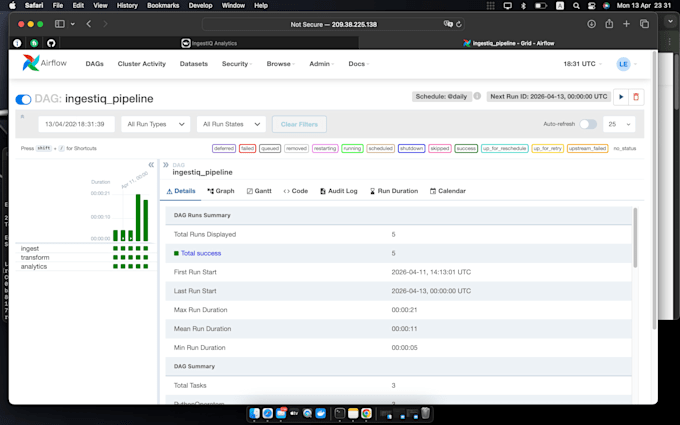
Warum diese Architektur funktioniert:
Modulares Design: Pipelines sind von Quellen entkoppelt, um sichere Skalierung zu ermöglichen.
Konsequenzschicht: Validierung & Statusverwaltung für 100% Genauigkeit.
Bronze/Silber-Speicher: Roh- und verarbeitete Schichten zur Optimierung der Leistung.
Agnostische Bereitstellung: Docker-Lösungen für jede Cloud- oder On-Premise-Umgebung.
Individuelle Dashboards: Streamlit-Oberfläche in jedem Projekt enthalten.
Zusammenarbeit & Grenzen: Ich liefere autonome Systeme mit klaren Grenzen:
Umfang: Deckt definierte Quellen & Deployment ab. Neue Logik/Integrationen sind separate Iterationen.
Zuverlässigkeit: Proaktives Fehlerhandling inklusive. 24/7-Überwachung oder Serverwartung sind separate Dienstleistungen.
Eigentum: Dokumentation für eigenständige Wartung bereitgestellt.
Stack: Python, SQL, Airflow, Docker, Postgres, DuckDB.
Kontaktiere mich vor der Bestellung, um die Anforderungen abzustimmen!

Zielplattform:
PostgreSQL
•
mySQL
•
Andere
Tools und Plattformen:
Andere