Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Cloud-Dateningenieur, BigQuery, Snowflake, dbt, Python, ETL
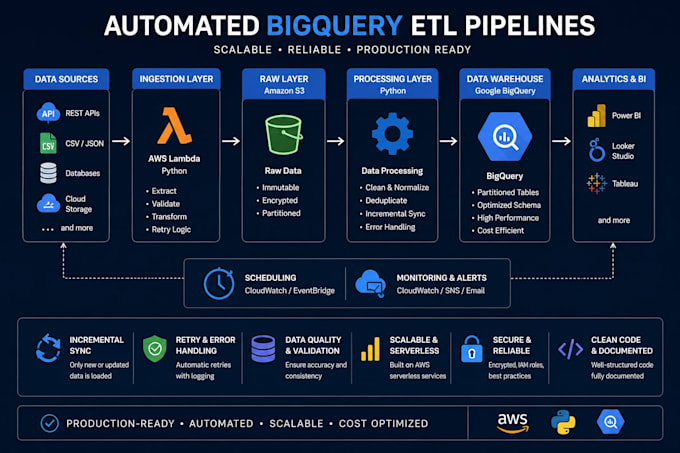
Baue eine skalierbare und produktionsreife ETL-Pipeline von APIs, CSV, JSON, Datenbanken oder Cloud-Speicher direkt in Google BigQuery.
Ich spezialisiere mich auf automatisierte Datenpipelines auf Python-Basis für Analytics, Reporting, Power BI, Looker Studio, Tableau und Business-Intelligence-Plattformen.
Zu den Services gehören:
API BigQuery-Ingestion
Inkrementelles Laden von Daten
Historische Backfills
JSON / CSV-Normalisierung
Automatisierte geplante Pipelines
AWS Lambda / serverlose Architektur
Retry- & Fehlerbehandlung
Logging & Monitoring
Data Deduplication
Partitionierte BigQuery-Tabellen
Raw Staging Curated Architektur
dbt-fertige Warehouse-Strukturen
Technologien:
- Python
- BigQuery
- AWS Lambda
- S3 / GCS
- Airflow / Prefect
- dbt
- REST APIs
Typische Anwendungsfälle:
- E-Commerce-Analytics
- Finanzberichte
- Marketing-Dashboards
- CRM-Integrationen
- Automatisierte Berichtssysteme
Ich konzentriere mich auf skalierbare, wartbare und produktionsreife Architekturen anstelle von einfachen Skripten.
Bitte kontaktiere mich vor der Bestellung für individuelle oder groß angelegte Projekte.
Revisionsarbeiten schließen keine größeren Scope-Änderungen oder zusätzliche Integrationen ein.





Automatische Übersetzung
Unterstützt du große Datensätze?
Ja. Ich entwerfe skalierbare Pipelines für Millionen von Datensätzen und Produktions-Workloads.
Kannst du auf AWS deployen?
Ja. Ich kann serverlose Architekturen mit Lambda, S3, Step Functions und CloudWatch bereitstellen.
Kannst du die BigQuery-Kosten optimieren?
Ja. Ich nutze Partitionierung, Clustering, inkrementelle Verarbeitung und optimierte Abfrage-Muster.
Welche Architektur bevorzugst du für deine Datenpipeline?
Ich kann die Pipeline entweder mit AWS-native oder GCP-native Architektur bauen, abhängig von deiner bestehenden Infrastruktur, deinem Budget und deinen Reporting-Anforderungen. 1. API → Cloud Run / Cloud Function → GCS Raw → BigQuery 2. API → Lambda → S3 Raw → BigQuery Data Transfer Service → BigQuery
Kannst du inkrementelle ETL-Pipelines bauen?
Ja. Ich bevorzuge inkrementelle Verarbeitung stark gegenüber vollständigen Reloads, um Skalierbarkeit, geringere BigQuery-Kosten und bessere Zuverlässigkeit zu gewährleisten.
Unterstützt du dbt-Transformationen?
Ja. Ich kann dbt-Modelle für Staging, Cleaning, Joins, Business-Logic und kuratierte Analytics-Tabellen erstellen.
Kannst du mit bestehenden Data Warehouses oder Pipelines arbeiten?
Ja. Ich kann bestehende BigQuery-, AWS- oder ETL-Umgebungen verbessern, optimieren, debuggen oder erweitern.
Kannst du Power BI oder andere BI-Tools integrieren?
Ja. Ich kann analytics-fähige Datensätze für Power BI, Looker Studio, Tableau und SQL-Analytics vorbereiten.
Bietest du Überwachung und Fehlerbehandlung an?
Ja. Produktionspipelines beinhalten Logging, Retry, Alerts und Monitoring, um Zuverlässigkeit und Betriebssicherheit zu verbessern.
Kannst du historische Backfills und große API-Datensätze verarbeiten?
Ja. Ich kann Pipelines für historische Synchronisation, paginierte APIs und groß angelegte Datensätze mit optimierten Lade-Strategien bauen.