Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Ukraine
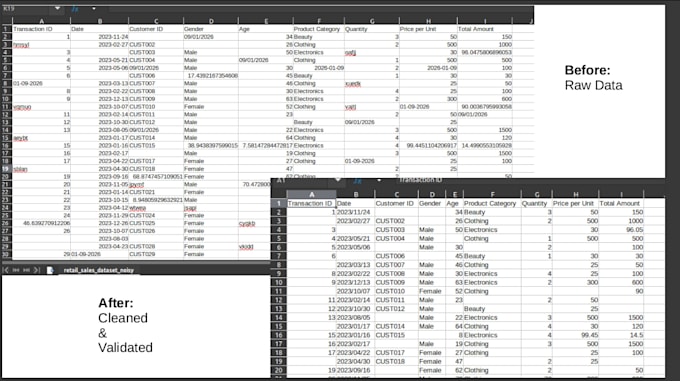
Databridge ist eine leistungsstarke lokale Datenverarbeitungs-Engine, die darauf ausgelegt ist, unordentliche, inkonsistente Daten in ein strukturiertes SQL-Lager umzuwandeln. Es automatisiert den Datenbereinigungs-Prozess und ersetzt hunderte von manuellen Stunden durch ein einziges, sicheres Tool.
Zentrale Funktionen:
Python-Automatisierung in Bestform: Perfekt für E-Commerce, Finanz- und Marketingabteilungen, die mit fragmentierten Lieferantenberichten arbeiten.


Technologie:
Python
•
Andere
Automatische Übersetzung
Wie geht die Engine mit nicht-standardisierten Headern um?
Sie verfügt über einen robusten Regex-basierten Normalizer. Jeder Header wie __&&UsER+nAME🥰 wird automatisch zu user_name bereinigt. Es nutzt fuzzy matching, um die richtigen Spalten zu finden, auch wenn deren Namen oder Reihenfolge zwischen den Dateien variieren.
Was sind die spezifischen Regeln für die Datenumwandlung?
Wir bieten eine wachsende Bibliothek von Typen an: int, float, date, str, sowie spezialisierte alpha (Buchstaben nur) und identifier. Alle Typen verwenden strenge Validierung und Fehlerumwandlung, um "schmutzige" Daten sicher zu handhaben. Es werden ständig neue benutzerdefinierte Typen zum Engine hinzugefügt.
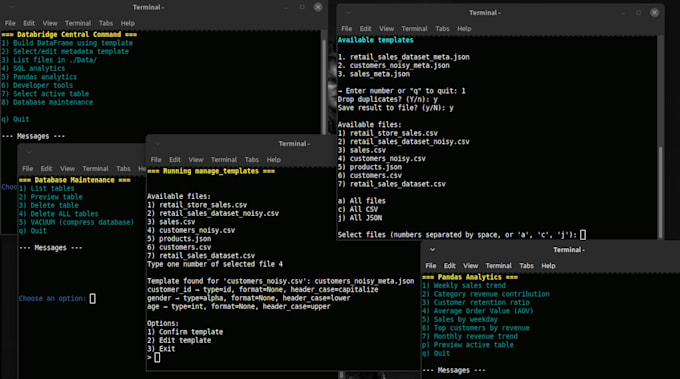
Wie funktionieren eure JSON-Vorlagen?
Vorlagen fungieren als Vertrag. Die Engine nutzt regex, um Zielspalten unabhängig von deren Namen oder Reihenfolge zu finden. Danach wandelt sie die Daten strikt in die gewählten Typen (int, float, date) um und formatiert sie. Wenn eine Zeile Daten fehlt oder die Validierung nach Vorlage scheitert, wird sie sicher ignoriert.
Kann ich viele verschiedene Dateien gleichzeitig verarbeiten?
Ja, im Enterprise-Tarif ermöglicht der "Batch Mode", die Engine auf einen Ordner zu zeigen. Sie durchläuft jede Datei, ignoriert irrelevante Daten nach deiner Vorlage und baut Zeile für Zeile eine konsolidierte Datenbank auf.
Wie verwalte ich die Ausgabedatenbank?
Das Tool beinhaltet einen Database Service. Du kannst zwischen aktiven Tabellen wechseln, alte Datensätze löschen und den VACUUM-Befehl ausführen, um die SQLite-Datei zu defragmentieren und Speicherplatz freizugeben.
Was sind die Systemvoraussetzungen?
Das ist ein Python-basiertes CLI-Tool. Es erfordert Python 3.9+ auf deinem Rechner. Alle Verarbeitungen erfolgen lokal, die Leistung hängt also von deiner CPU/RAM ab, aber die Engine ist für Hochgeschwindigkeits-Batch-Operationen optimiert.