Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Ich entwerfe und baue skalierbare Datenpipelines, die auf die Bedürfnisse deines Unternehmens zugeschnitten sind. Mit Python, PySpark, SQL und AWS automatisiere ich Datenaufnahme, -transformation und -speicherung, um saubere, zuverlässige und für Analysen bereitstehende Daten zu liefern. Ich führe Datenqualitätsprüfungen durch, wie das Erkennen fehlender Werte, das Entfernen von Duplikaten, die Formatüberprüfung und die Schema-Validierung, um die Datenintegrität sicherzustellen.
Außerdem erstelle ich interaktive Dashboards und Berichte mit Amazon QuickSight und Tableau, damit du KPIs überwachen und datenbasierte Entscheidungen leicht treffen kannst. Ob ETL-Workflows, Datenvalidierung, Cloud-Deployment oder Reporting-Lösungen – ich liefere optimierte, skalierbare Systeme.
Ich lege Wert auf klare Kommunikation, pünktliche Lieferung und kontinuierlichen Support, damit deine Dateninfrastruktur mit deinem Unternehmen wächst. Lass uns deine Rohdaten in umsetzbare Erkenntnisse verwandeln!
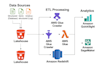
Expertise:
Big Data
•
Datenvalidierung
•
etl
•
Transformation
•
QA
•
SQL