Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD



Automatische Übersetzung
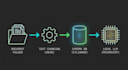
Vertrauliche Daten nicht mehr in die Cloud leaken lassen. Mit deinen Dokumenten 100% lokal und sicher chatten.
Hast du genug davon, vertrauliche Geschäftsdokumente, Verträge oder Forschungsarbeiten in allgemeine Cloud-APIs hochzuladen? Ich baue maßgeschneiderte Retrieval-Augmented Generation (RAG)-Pipelines, die komplett auf deiner lokalen Hardware oder privaten Servern laufen. Als Data Engineer aus Deutschland spezialisiere ich mich auf den Aufbau hochsicherer, GDPR-konformer KI-Architekturen.
Meine Kernleistungen:
Perfekt für Rechtsteams, medizinische Praxen oder Forscher, die sichere Wissensgewinnung benötigen.
Bitte kontaktiere mich vor der Bestellung, um deine Hardware-Spezifikationen zu besprechen!
Data Engineer, Local AI Specialist and Master of Urban Development
Sprachen
Automatische Übersetzung
Automatische Übersetzung
Brauche ich einen High-End-PC, um diese lokale AI auszuführen?
Ja. Für reibungslose LLM-Inferenz (wie Llama 3.1) ist eine GPU mit mindestens 8GB VRAM (z.B. RTX 3060/4060/5060) oder ein Apple M-Chip (16GB+ RAM) erforderlich. Nur-CPU-Läufe sind möglich, aber langsam. Schick mir vor der Bestellung deine Hardware-Spezifikationen!
Sind meine Daten wirklich 100% privat und sicher?
Absolut. Im Gegensatz zu ChatGPT läuft diese RAG-Pipeline komplett auf deinem lokalen Rechner. Deine PDFs und internen Dokumente werden vektorisiert und in einer lokalen Datenbank (z.B. ChromaDB) gespeichert. Keine Daten werden an OpenAI oder irgendeine Cloud-API gesendet.
Wie vermeidest du Halluzinationen bei der AI?
Ich setze eine strenge RAG-Architektur mit gezielten System-Prompts (Temperatur 0.0) um. Das LLM ist gezwungen, nur den Kontext aus deinen PDFs zu verwenden. Wenn die Antwort nicht in deinen Dokumenten steht, sagt die AI, dass sie es nicht weiß, um erfundene Fakten zu vermeiden.
Welche Dokumententypen kann die AI lesen?
Ich unterstütze PDF, TXT, CSV und Markdown. Für komplexe PDFs (wie technische Handbücher oder DIN-Normen) nutze ich fortschrittliches Parsing (PyMuPDF), um das Layout zu bewahren. So erhält das Embedding-Modell sauberen, kontextreichen Text.
Unterstützt die AI Sprachen außer Englisch?
Ja! Ich verwende modernste mehrsprachige Embedding-Modelle (BAAI/bge-m3) und LLMs (Llama 3.1). Sie sind hervorragend in Deutsch, Französisch, Spanisch usw. Die AI kann nahtlos ein deutsches Dokument lesen und in Englisch präzise antworten oder umgekehrt.


