Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
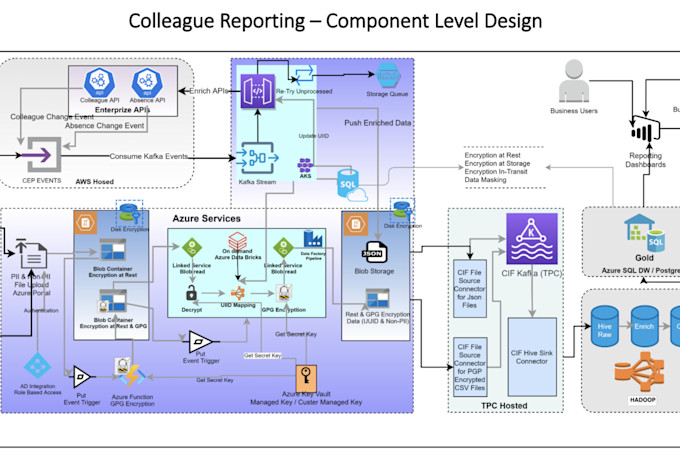
Senior Data Engineer: AWS, Azure, Spark, ETL Pipelines und Data Architecture
Hast du Schwierigkeiten mit langsamen oder unzuverlässigen Datenpipelines? Ich entwerfe und baue produktionsreife ETL-Pipelines auf AWS und Azure, die schnell, skalierbar und langlebig sind.
Was du bekommst:
- End-to-End-Design und Implementierung von ETL-Pipelines
- Leistungsoptimierung bei Apache Spark (PySpark, Scala)
- AWS-Einrichtung: Glue, Lambda, Step Functions, S3, Redshift
- Azure-Einrichtung: Databricks, Data Factory, Azure Data Lake Gen2
- Datenvalidierung, Fehlerbehandlung und Überwachung
- Vollständige Dokumentation und Übergabe
Ideal Für:
- Unternehmen mit langsamen oder fehlerhaften Datenpipelines
- Teams, die von On-Prem auf AWS oder Azure migrieren
- Projekte, die Spark-Optimierung und -Tuning benötigen
- Entwicklung von Echtzeit- oder Batch-ETL
Warum du mich wählen solltest:
Mehr als 5 Jahre Erfahrung im Aufbau von Unternehmensdatenpipelines in den Branchen Einzelhandel, IoT und Finanzen. Ich habe Pipelines verarbeitet, die täglich Millionen von Datensätzen bearbeiten, und bringe diese Expertise auch in dein Projekt ein.



Zielplattform:
Amazon Redshift
•
Amazon S3
Tools und Plattformen:
AWS Glue DataBrew