Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Senior Data Engineer, Spark, Scala, AWS, Airflow, Kafka, Big Data
Suchst du einen zuverlässigen PySpark Data Engineer, der deine ETL-Pipelines baut oder optimiert?
Du bist hier genau richtig.
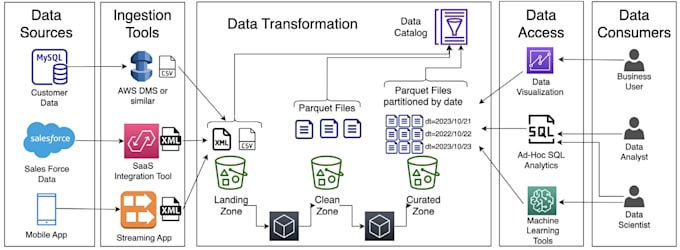
Ich bin Pankaj, ein Data Engineer mit über 3 Jahren Erfahrung bei Paytm, wo ich über 200 Produktions-ETL-Pipelines gebaut habe, die täglich mehr als 5 TB verarbeiten, mit PySpark, Airflow, AWS und Kafka.
Dieses Gig konzentriert sich zu 100 % darauf, schnelle, skalierbare und saubere PySpark ETL-Lösungen für dein Business zu liefern.
Was ich für dich tun kann
Warum du mich wählen solltest
Technologien, die ich verwende
Hast du eine individuelle Anforderung?
Schreib mir jederzeit, ich antworte schnell.
Lass uns etwas Skalierbares aufbauen.

Automatische Übersetzung
Was brauchst du von mir, um anzufangen?
Datenbank-/API-Zugang, Beispiel-Daten, SQL-Logik oder Problemstellung.
Kannst du eine Verbindung zu meiner Datenbank oder API herstellen?
Ja — MySQL, PostgreSQL, MongoDB, APIs, S3 und mehr.
Optimierst du bestehende Pipelines?
Ja — Ich spezialisiere mich auf Laufzeitoptimierung und Debugging.
Kannst du AWS-Services integrieren?
Ja — Glue, S3, EMR, Lambda, Athena.
Können Sie ein NDA unterzeichnen?
Ja — Ich kann bei Bedarf unter NDA arbeiten.