Führen Sie LLaMA-Modelle lokal auf Ihrer eigenen Hardware aus und profitieren Sie von schneller, privater KI! Ich bin spezialisiert auf die Bereitstellung von LLaMA-LLMs für Einsteiger und Entwickler mit llama.cpp , einer schlanken C/C++-Inferenz-Engine für leistungsstarke lokale Inferenz. Sie erhalten ein komplettes Setup für Windows und Linux – ohne Cloud, ohne laufende Kosten und mit voller Kontrolle über Ihre KI-Modelle.
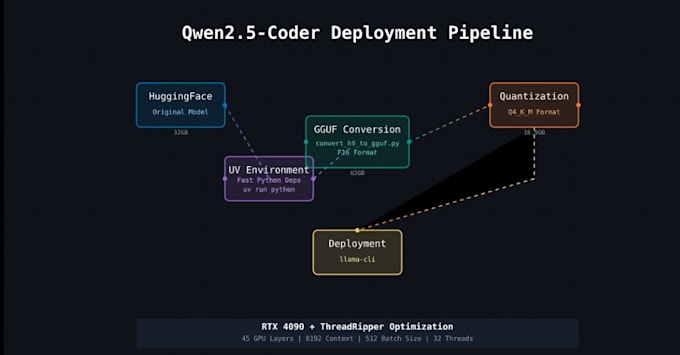
- Lokale Installation: Ich installiere und konfiguriere die neueste LLaMA (2/3) oder ein kompatibles GGUF-Modell auf Ihrem Rechner. Egal ob Windows, Linux oder Mac – ich kümmere mich um die Einrichtung der Umgebung, die Abhängigkeiten und die Erstellung der llama.cpp-Datei oder die Installation der Binärdatei (medium.com).
- GPU- und CUDA-Optimierung: Dank NVIDIA CUDA-Unterstützung aktiviere ich die GPU-Beschleunigung (und Multithreading), um die Inferenz zu beschleunigen . Durch Optimierungen in llama.cpps und Modellquantisierung (4-Bit/8-Bit) reduziere ich den Speicherverbrauch, sodass selbst große Modelle flüssig laufen (quantisierte Modelle sind deutlich kleiner bei gleichzeitig hoher Genauigkeit).
- Feinabstimmung & Benutzerdefinierte Daten: Im Premium-Paket feinabgestimmt optimiere ich Ihr LLaMA-Modell anhand Ihres eigenen Datensatzes mithilfe von LoRA-Adaptern ( LoRA ermöglicht es uns, das Modell an Ihre Bedürfnisse anzupassen, indem nur die Adaptergewichte trainiert werden).