Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Dateningenieur
Hast du Schwierigkeiten mit verstreuten Daten, defekten Pipelines oder langsamen Datenbanken? Ich helfe dir, widerstandsfähige und skalierbare Data Engineering-Lösungen zu entwickeln.
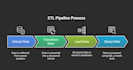
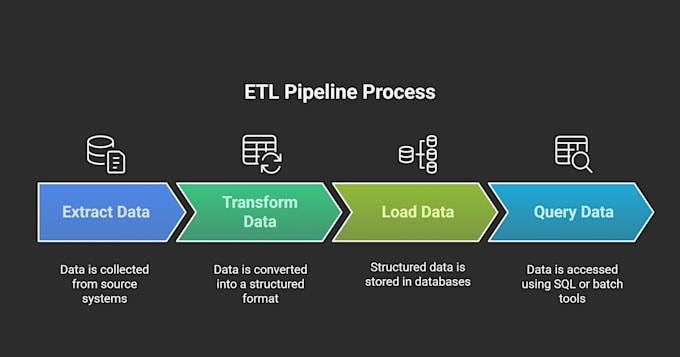
Als Senior Data Engineer spezialisiere ich mich auf den Aufbau robuster ETL/ELT-Pipelines, das Design von Data Warehouses (Snowflake, BigQuery) und die Einrichtung von Echtzeit-Streaming-Infrastruktur.
Was ich in diesem Gig anbiete:
Egal, ob du ein einfaches Python-Skript zum Scrapen von API-Daten brauchst oder eine riesige Enterprise-Data-Lake-Architektur – ich liefere hochoptimierte und kosteneffiziente Lösungen.
(Bitte sende mir vor der Bestellung eine Nachricht, um deine Datenquellen und Architektur-Anforderungen zu besprechen!)