Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
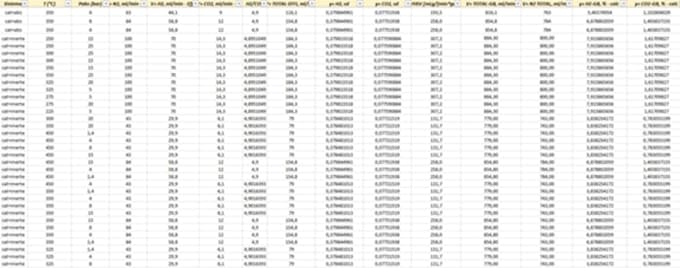
Ich habe ein maßgeschneidertes Machine-Learning-Klassifikationsmodell für chemische Reaktionsdaten entwickelt.
Mit experimentellen Variablen wie Temperatur, Druck, Zufuhrempfehlung und Umwandlungsraten kann das Modell genau zwischen verschiedenen Katalysatorsystemen und Reaktionstypen unterscheiden.
Perfekt für Forscher, Chemieingenieure und Labore, die Muster extrahieren oder Reaktionsanalysen automatisieren möchten.
Die Lieferung umfasst das trainierte Modell, einen Leistungsbericht (Präzision, Recall, F1) und visuelle Einblicke.


Expertise:
Klassifizierung
•
Entscheidungsbäume
Programmiersprache:
Python
Frameworks:
scikit-learn
•
Panda
APIs:
Microsoft Computer Vision AI
Tools:
Jupyter-Notizbuch
•
Excel
Automatische Übersetzung
Was brauchst du von mir, um anzufangen?
Ein Musterdatensatz (CSV/Excel) und eine kurze Beschreibung der Reaktionssysteme und Zielklassen.
Welches Problem löst du?
Ich erstelle einen Machine-Learning-Klassifikator, um Reaktionstypen/-systeme anhand experimenteller Variablen (z.B. P, T, Zufuhrempfehlung, WHSV, Umwandlungen) zu unterscheiden.
Welche Deliverables erhalte ich?
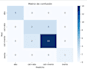
Trainiertes Modell, bereinigtes Notebook/Skript, Leistungsbericht (Präzision/Recall/F1), Verwirrungsmatrix und kurze Empfehlungen.
Welche Algorithmen verwendest du?
Standardmäßig Baum-Ensembles (Random Forest/XGBoost); auf Wunsch kann ich auch SVM/LogReg testen.
Kannst du mit unausgeglichenen Klassen oder kleinen Datensätzen umgehen?
Ja—mit Techniken wie Klassen-Gewichten, SMOTE/ADASYN und sorgfältiger Kreuzvalidierung.
Was, wenn meine Daten fehlende Werte oder verrauschte Spalten haben?
Ich führe leichte Vorverarbeitung durch: Typkorrekturen, Imputation und Feature-Auswahl nach Bedarf.
Erklärst du die Entscheidungen des Modells?
Ja—Merkmalsbedeutung und optionale SHAP-Diagramme, um zu zeigen, was die Vorhersagen antreibt.
Sind meine Daten vertraulich?
Absolut—deine Daten bleiben privat; ich kann bei Bedarf eine NDA unterschreiben.