Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD


Automatische Übersetzung
Hör auf, Geld für unnötige AI-Aufrufe zu verbrennen!
Die meisten AI-Apps verschwenden 40 % bis 80 % ihres Budgets bei redundanten LLM-Aufrufen. Ich bin hier, um dir zu helfen, den Blutverlust zu stoppen.
Ich werde einen Produktionsbereiten semantischen Cache erstellen, der sich an vergangene Anfragen erinnert und Antworten sofort bereitstellt, wodurch deine Kosten sinken und deine App sich blitzschnell anfühlt.
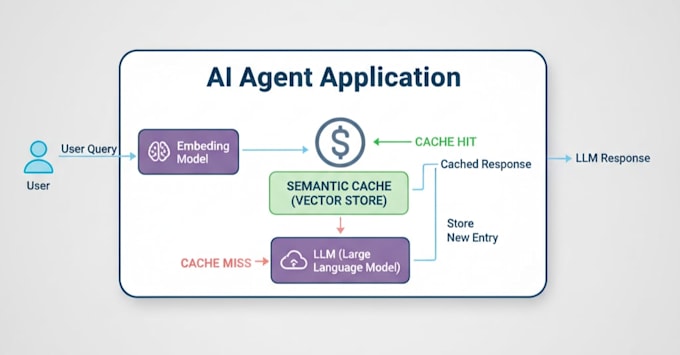
Was ist semantisches Caching?
Standard-Caching ist „dumm“ – es braucht eine 100%ige Wort-für-Wort-Übereinstimmung. Semantisches Caching ist clever. Mit Vektor-Embeddings versteht dein System die Absicht. Wenn Nutzer A fragt „Wie ist das Wetter?“ und Nutzer B fragt „Wie ist die Prognose?“, weiß das System, dass sie dasselbe meinen. Es liefert die gespeicherte Antwort sofort, ohne deine API zu belasten.
Was ist in diesem Gig enthalten?
Code, Scrape, Automate, FullStack Developer for Data and AI
Sprachen
Automatische Übersetzung
Automatische Übersetzung
Verursacht Caching nicht, dass die AI „alte“ oder „falsche“ Informationen liefert?
Nicht, wenn es richtig gemacht wird. Wir implementieren „Cache Invalidation“ und „Time-to-Live“ (TTL)-Einstellungen. Wenn deine Daten häufig aktualisiert werden, kann der Cache so eingestellt werden, dass er jede Stunde abläuft. Bei statischen Daten kann er ewig bestehen bleiben. Außerdem passen wir die „Ähnlichkeits-Schwelle“ an, sodass nur wirklich ähnliche Fragen einen Cache-Hit auslösen.
Wie viel Geld spare ich wirklich?
Das hängt von deiner „Cache-Hit-Rate“ ab. Für Support-Bots oder FAQs fragen Nutzer oft ähnliche Fragen, was 60-90 % Einsparungen bedeutet. Bei sehr kreativen oder einzigartigen Aufgaben-Bots liegen die Einsparungen meist bei 20-30 %.
Sind meine Daten sicher?
Völlig. Der Cache wird auf deiner Infrastruktur (oder deiner bevorzugten Cloud-Datenbank) gehostet. Ich speichere deine Daten nicht auf meinen eigenen Servern.
Funktioniert das mit jedem LLM?
Ja. Egal, ob du OpenAI’s GPT-4o, Google Gemini 1.5, Claude 3.5 oder sogar lokale Modelle wie Llama 3 nutzt, die Caching-Schicht sitzt vor der API und macht sie provider-unabhängig.