Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD





Automatische Übersetzung
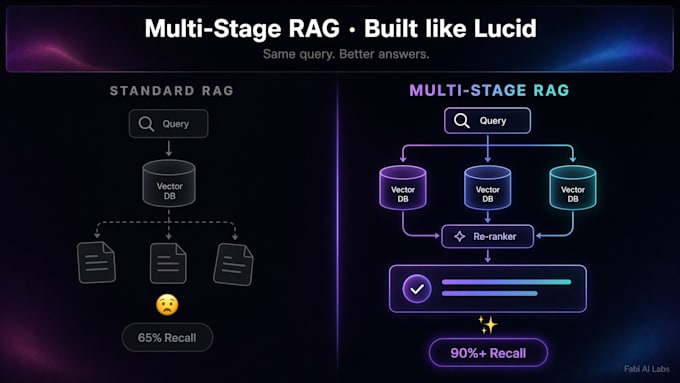
Standard RAG stößt bei zusammengesetzten Fragen an Grenzen. Ein Einzelfragen-Bot ruft nur Abschnitte ab, die "Rückerstattung" erwähnen, und verpasst Nuancen – Preismodelle, Schadensklauseln, individuelle Bestellrichtlinien.
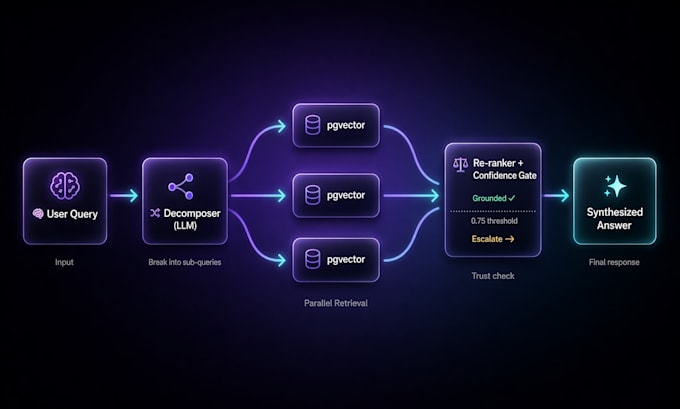
Multi-Stage RAG ist anders. Es zerlegt die Fragen in Unterfragen, ruft sie parallel ab, bewertet sie neu und synthetisiert die Ergebnisse. Die Erkennungsrate steigt von 65 % auf über 90 %. Antworten bleiben fundiert. Halluzinationen sinken.
WAS DU BEKOMMST:
- Query-Decomposition (LLM zerlegt zusammengesetzte Fragen in gezielte Suchen)
- HyDE hypothetische Dokumenten-Embedding für die Abfrage
- Re-Ranking + Vertrauensbewertung vor der Antwortgenerierung
- 4 Schutzmaßnahmen: menschliche Übergabe, Unsicherheits-Gate, kein Gaslighting, Transparenz
- Individueller Evaluations-Testset mit messbarer Retrieval-Qualität
- Admin-Dashboard für Gesprächs- und Retrieval-Debugging (Premium)
TECHNOLOGIE: Python/TypeScript, Supabase pgvector, OpenAI/Anthropic/Gemini APIs, eigener Re-Ranker.
WARUM MULTI-STAGE: Single-Query RAG funktioniert bei einfachen FAQs. Wenn dein Bot Preisspielräume oder zusammengesetzte Fragen behandelt – brauchst du das hier.
Das ist, was ich in Lucid eingebaut habe. Gleiche Architektur für dein Fachgebiet, abgestimmt auf deine Stimme.
Schick mir deinen Anwendungsfall plus 10 schwierige Fragen, die dein aktueller Bot nicht beantworten kann. Ich antworte mit dem Umfang.
AI Developer and Creator of Lucid
Sprachen
Automatische Übersetzung
Automatische Übersetzung
Wie unterscheidet sich Multi-Stage RAG von einfachem RAG?
Einfaches RAG führt eine Vektor-Suche pro Frage durch. Bei zusammengesetzten Fragen liegt die Erkennungsrate bei etwa 65 %. Multi-Stage RAG zerlegt die Frage, sucht parallel, bewertet neu. Die Erkennungsrate steigt auf über 90 %. Weniger Halluzinationen, bessere fundierte Antworten.
Wird das bei großem Umfang mehr kosten als einfaches RAG?
Oft weniger. Die Zerlegung nutzt günstige Modelle (Gemini Flash ca. 0,10 $ pro 1 Mio. Tokens). Die endgültige Antwort erfolgt mit einem Premium-Modell. Einfaches RAG zahlt für jeden Aufruf Premium-Preise. Bei mehr als 10.000 Gesprächen im Monat ist Multi-Stage oft 30-50 % günstiger.
Was, wenn meine Dokumente unordentlich oder unstrukturiert sind?
Wird im Rahmen des Umfangs behandelt. Ich normalisiere Dokumente während der Ingestion – durch Chunking nach semantischen Grenzen (nicht naive Absatzaufteilung), Entfernen von Boilerplate, Hinzufügen von Metadaten für filterbasiertes Retrieval. Unordentliche Eingaben sind die Standardannahme, keine Ausnahme.
Bringst du deine eigenen API-Schlüssel mit?
Ja – gleiche Regel wie bei meinem Starter Bot Gig. Du besitzt die OpenAI / Anthropic / Gemini Konten, zahlst direkt ohne Aufschlag, hast volle Kontrolle. Ich helfe dir, die kosteneffizienteste Modellmischung für dein Traffic-Volumen zu wählen.