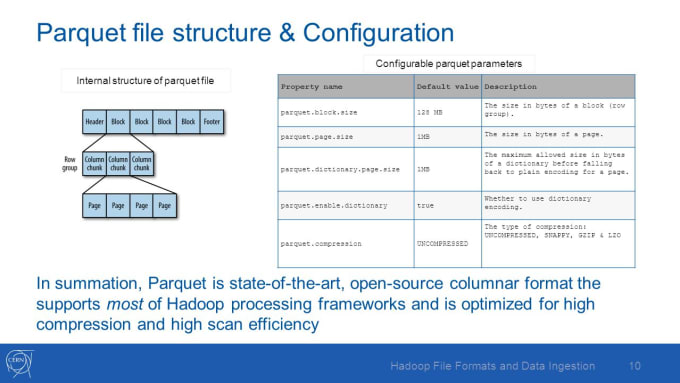
Self-describing data embeds the schema or structure with the data itself. Hadoop use cases drive the growth of self-describing data formats, such as Parquet and JSON, and of NoSQL databases, such as HBase. These formats and databases are well suited for the agile and iterative development cycle of Hadoop applications and BI/analytics. Optimized for working with large files, Parquet arranges data in columns, putting related values in close proximity to each other to optimize query performance, minimize I/O, and facilitate compression. Parquet detects and encodes the same or similar data using a technique that conserves resources.