Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Softwareentwickler
Professionelles Big Data Engineering für skalierbare, produktionsreife Infrastruktur
Ich liefere praktische, end-to-end Big Data Lösungen von der Architekturplanung bis zur Implementierung und Optimierung mit branchenüblichen Tools. Jede Lösung ist auf deine Ziele, Infrastruktur und Arbeitslastanforderungen zugeschnitten, um Leistung, Skalierbarkeit und langfristige Stabilität zu gewährleisten.
Enthaltene Leistungen:
Warum Kunden diesen Service wählen:


Sprache:
Englisch
•
Urdu
Technische Expertise:
Apache NiFi
•
Apache-Funken
•
hadoop
•
Andere
Industrie:
Datenanalyse
Automatische Übersetzung
Welche Arten von Big Data Projekten betreust du?
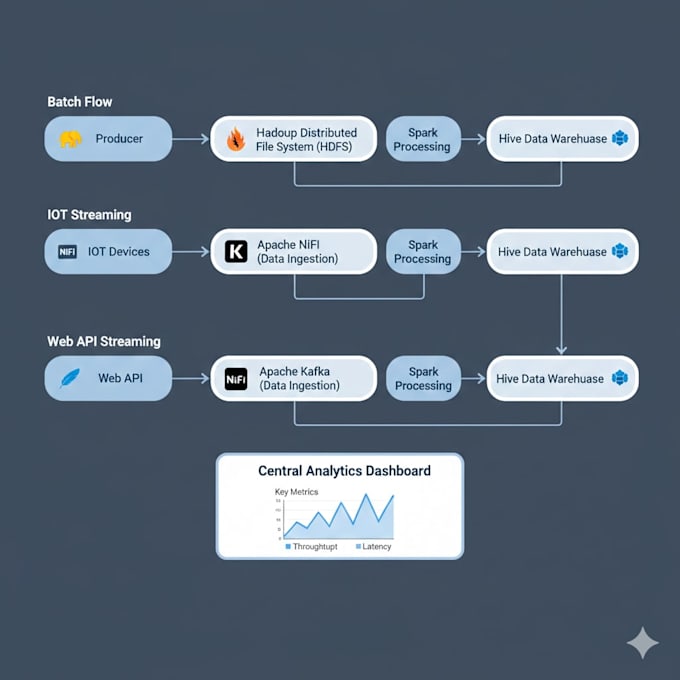
Ich kümmere mich um Einrichtung, Einsatz, Optimierung und Fehlerbehebung von Big Data Umgebungen mit Hadoop, Spark, Kafka, Hive, NiFi und verwandten Tools — von kleinen Proof-of-Concept-Systemen bis hin zu Produktionsclustern.
Kannst du ein komplettes Hadoop- oder Spark-Cluster von Grund auf einrichten?
Ja. Ich kann voll funktionsfähige Cluster entwerfen und bereitstellen, inklusive Konfiguration, Leistungstuning und Validierung, um Stabilität zu gewährleisten.
Unterstützt du Echtzeit-Datenstreaming-Pipelines?
Absolut. Ich baue Kafka-basierte Streaming-Pipelines auf und integriere sie mit Spark oder NiFi für effiziente Echtzeit-Datenverarbeitung.
Stellen Sie Unterlagen zur Verfügung?
Ja. Es ist eine klare Dokumentation enthalten, damit du dein System verstehen, verwalten und pflegen kannst.
Wie fangen wir an?
Teile einfach deine Anforderungen, Infrastrukturdetails und Ziele — ich schlage den besten Implementierungsplan vor.