Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD



Automatische Übersetzung
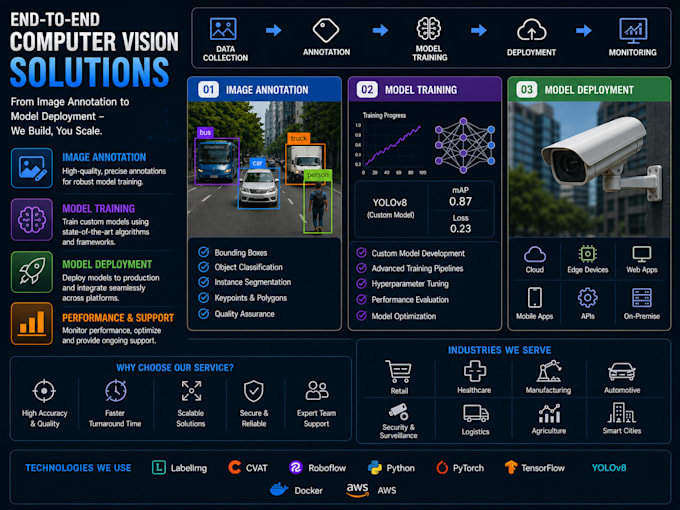
Ich annotiere deine Bilder und trainiere ein benutzerdefiniertes YOLO-Modell, das DEINE Objekte erkennt, nicht nur generische vortrainierte Demos.
Ich bin Mitglied des NVIDIA Inception-Programms mit einem Python AI/ML-Team, das Objekterkennungssysteme in der Fertigung, Sicherheit, Gastronomie und Sportanalytik in 6 Ländern eingesetzt hat.
WAS ICH BEREITSTELLE:
SCHRITT 1 ANNOTATION & LABELING
Bounding-Box-, Polygon- oder Keypoint-Annotation
Tools: CVAT, LabelImg, Roboflow, Label Studio, YOLO-Format-Export (yaml + txt Labels)
SCHRITT 2 DATENSATZVORBEREITUNG
Augmentation, Aufteilung in train/val/test, Qualitätsprüfung
SCHRITT 3 YOLO-MODEL-TRAINING
Benutzerdefiniertes Training mit YOLOv8 auf deinem Datensatz, GPU-beschleunigt auf NVIDIA CUDA, mAP, Präzision, Recall und Verwirrungsmatrix-Bericht
SCHRITT 4 DEPLOYMENT (Nur Premium)
TensorRT-Optimierung für 3-5x schnellere Inferenz, FastAPI-Inferenz-Endpunkt, Python-Skript einsatzbereit
WAS ICH GESCHAFFEN HABE:
Fußballspieler-Tracking mit 22 Spielern gleichzeitig
Rauch- und PSA-Erkennung auf NVIDIA Jetson Edge Hardware
Überwachung der Hygienevorschriften in Restaurantsküchen
Du erhältst: gekennzeichneten Datensatz, trainierte Modellgewichte, Inferenzskript und Trainingsbericht.
Kontaktiere mich vor der Bestellung mit deinen Bildern und deinem Anwendungsfall.
AI App Development Expert, Computer Vision, OpenCV, Object Detection
Sprachen
Automatische Übersetzung
Automatische Übersetzung
Welche Bildformate akzeptieren Sie?
JPG, PNG, BMP, TIFF und Video-Frames aus MP4. Falls nötig, kann ich Frames aus deinem Video extrahieren.
Was, wenn ich noch keine gelabelten Daten habe?
Das ist kein Problem. Annotation ist Schritt 1. Sende rohe Bilder und beschreibe, welches Objekt erkannt werden soll.
Wie viele Bilder brauche ich für gute Genauigkeit?
Mindestens 200 pro Klasse für grundlegende Erkennung. Über 500 pro Klasse erzielen 85–92% mAP. Über 1000 sind 90–96%.
Kannst du mit medizinischen oder Satellitenbildern arbeiten?
Ja. Sende zuerst ein Beispielbild, und ich bestätige die Machbarkeit, bevor du bestellst.
Kannst du auf meinem Server statt Jetson deployen?
Ja. Ich setze via FastAPI auf AWS, Google Cloud oder jedem Linux-Server mit GPU-Unterstützung um.