Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Ingenieur, Beta-Leser und Übersetzer EN nach PT, schnell und zuverlässig
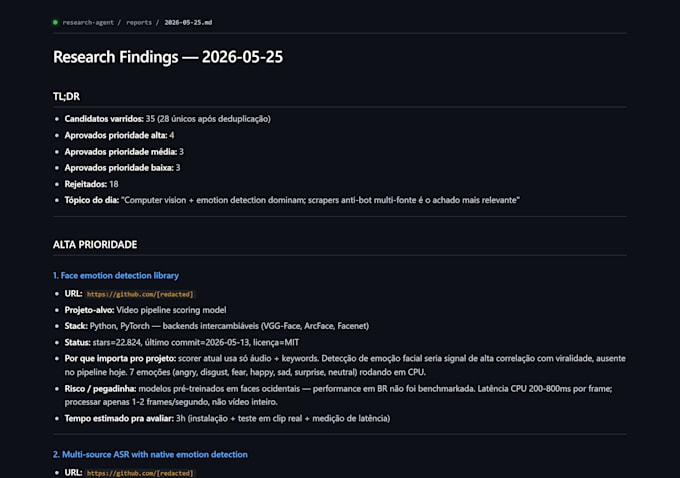
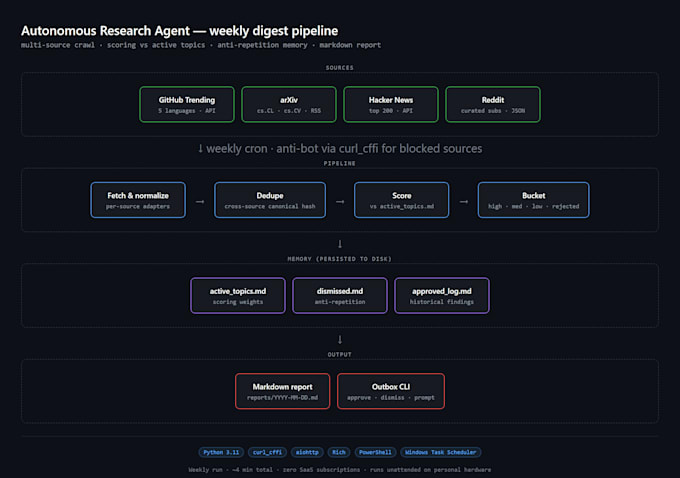
Die meisten Scraping-Gigs auf Fiverr brechen, sobald eine Seite Cloudflare Bot Management oder DataDome aktiviert. Ich schreibe Scraper, die DAS NICHT tun.
Verwendeter Stack:
Ziele, die ich erfolgreich gescraped habe:
Was ich liefere:
Rechtlicher Hinweis: Scraping liegt in deiner Verantwortung. Ich baue das Tool; du stellst sicher, dass du die ToS, robots.txt und die Gesetze deiner Gerichtsbarkeit einhältst.


Technologie:
Python
•
scrapy
•
Selen
•
Beautiful Soup
•
Dramatiker
Technik:
Automatisiert
Automatische Übersetzung
Funktioniert dieser Scraper für immer?
Nein. Anti-Bot-Abwehrmaßnahmen entwickeln sich weiter. Scraper brechen alle 3-12 Monate. Ich dokumentiere, WIE die Umgehung funktioniert, damit DU dich anpassen kannst – oder mich für Patches beauftragst.
Stellst du Proxys bereit?
Nein. Du kaufst Proxies (empfohlen Decodo oder BrightData Residential – 5-8$/GB). Ich konfiguriere die Rotationslogik im Scraper.
Kannst du Instagram / Facebook / LinkedIn scrapen?
Nein. Diese haben aggressive Rechtsteams und setzen die Durchsetzung aktiv durch. Ich lehne diese Anfragen ab. Andere Anti-Bot-Seiten sind in Ordnung.