Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD

Automatische Übersetzung
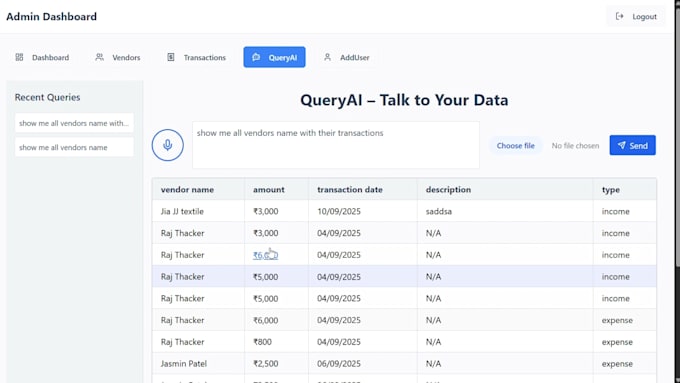
Willst du Informationen aus Dokumenten automatisiert extrahieren, statt manuell kopieren und einfügen? Ich entwickle Python-basierte Automatisierungslösungen, die Dateien schnell, präzise und in großem Umfang verarbeiten.
Ich habe Erfahrung im Aufbau von Dokumentenverarbeitungs-Workflows für Finanzberichte, Rechnungsbearbeitung, Automatisierung von Arbeitsblättern und strukturierte Datenpipelines.
Was ich für dich tun kann:
Daten aus Rechnungen, Quittungen, Formularen und Finanzdokumenten extrahieren
Tabellen und strukturierte Informationen aus komplexen Dateien verarbeiten
Mehrseitige Dokumente und gescannte Dateien mit OCR bearbeiten
Extrahierte Informationen in JSON, CSV, Excel oder datenbankfähige Formate umwandeln
Automatisierungsskripte oder API-basierte Workflows für die Integration in bestehende Systeme erstellen
Technologie-Stack: Python · pdfplumber · PyMuPDF · OCR · FastAPI · SQL
Lieferumfang: sauberer Code, Installationsanleitung, Dokumentation und Beispielausgaben zum Testen.
Bitte sende mir vor der Bestellung eine Beispiel-Datei und das erwartete Ausgabeformat, damit ich Umfang und Machbarkeit bestätigen kann.
Python Backend Developer with FastAPI REST APIs and AI Integration
Sprachen
Automatische Übersetzung
Automatische Übersetzung
Können Sie gescannte PDFs verarbeiten?
Ja, ich verwende OCR (Tesseract/AWS Textract) für gescannte Dokumente.
In welchem Format wird die Ausgabe sein?
JSON, CSV oder direkt in deine Datenbank – deine Wahl.
Kannst du PDFs automatisch nach einem Zeitplan verarbeiten?
Ja, ich kann eine automatisierte Pipeline im Rahmen des Standard- oder Premium-Pakets erstellen.