Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Über dieses Gig
Ich spezialisiere mich auf den Aufbau von multi-modalen Sprach- und Emotionserkennungssystemen, indem ich Audio- und Textmodalitäten kombiniere, um die Leistung und Genauigkeit zu verbessern.
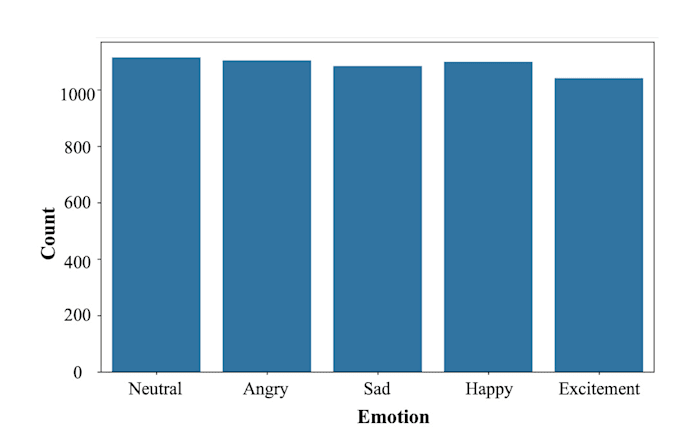
Mit praktischer Erfahrung bei der Arbeit an komplexen Datensätzen wie IEMOCAP und MELD habe ich maßgeschneiderte hybride Modelle mit Bi-LSTM und CNN entwickelt und erreiche bis zu 85 % Genauigkeit beim IEMOCAP-Datensatz. Ich erforsche auch aktiv Word2Vec und Transformer-basierte Architekturen für ein verbessertes kontextuelles Verständnis in der Sprache.
Weitere Details findest du in meinen Projekten und Forschungspapieren, die unten verlinkt sind.
Was ich anbiete:
Fühl dich frei, mir vor deiner Bestellung eine Nachricht zu schicken, um deine spezifischen Bedürfnisse zu besprechen.

Expertise:
Klassifizierung
•
Sprache und Audio
•
Prädiktive Analyse
Programmiersprache:
Python
•
Colab
APIs:
Andere
Tools:
Jupyter-Notizbuch
•
Amazon SageMaker
•
Colab
Frameworks:
scikit-learn
•
keras
•
PyTorch
•
Panda
•
tensorflow