Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Data Engineering, Azure, AWS, Databricks, Lakehouse, Spark, Fabric
Ist dein AWS-Datenbestand isoliert, unoptimiert oder treibt die Kosten in die Höhe?
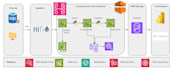
Als Senior Data Engineer mit 9 Jahren Erfahrung erstelle ich produktionsreife AWS ETL-Pipelines, die automatisiert, kosteneffizient und skalierbar sind. Ich spezialisiere mich darauf, fragmentierte S3-Daten in strukturierte, leistungsstarke Assets für Analytics und AI umzuwandeln.
Was ich für dich löse:
Warum dieses Gig wählen?
Ich schreibe nicht nur Skripte; ich baue Architekturen. Jede Pipeline, die ich liefere, ist so konzipiert, dass sie serverless ist, um deine monatliche AWS-Rechnung zu minimieren und gleichzeitig den Durchsatz zu maximieren. Von S3-Archivierungslogik bis automatischer Alarmierung sorge ich dafür, dass deine Daten verwaltet und zuverlässig sind.
Bist du bereit, dein AWS-Daten-Stack zu optimieren? Lass uns eine skalierbare Pipeline bauen


Automatische Übersetzung
Welche AWS-Services nutzt du für ETL-Pipelines?
Ich verwende AWS Glue, S3, Redshift, IAM, CloudWatch und Spark, je nach Projektbedarf.
Kannst du sowohl Batch- als auch inkrementelle Pipelines bauen?
Ja, ich entwerfe sowohl Batch- als auch inkrementelle Pipelines basierend auf Datenvolumen und Latenzanforderungen.
Übernimmst du die Datenqualitätsvalidierung?
Ja, ich implementiere Validierungschecks, Schema-Enforcement und Anomalieerkennung.
Kannst du bestehende AWS-Pipelines optimieren?
Absolut. Ich optimiere Leistung, Kosten und Zuverlässigkeit.
Stellst du Dokumentation bereit?
Ja, vollständige technische Dokumentation und Übergabe.
Unterstützt du API-Datenaufnahme?
Ja, REST APIs, Datenbanken und Dateiquellen.
Kannst du CI/CD Pipelines bauen?
Ja, auf Anfrage.
Wird die Sicherheit geregelt?
Ja, IAM-Rollen, Verschlüsselung und Zugriffskontrollen.
Unterstützt du Echtzeit-Pipelines?
Ja, bei Bedarf mit Kafka / Kinesis.
Bieten Sie Support nach der Lieferung an?
Ja, ich biete Support nach der Lieferung.


